Chapter 8. Collections and Enumerators
Many COM libraries are exposed as sets of objects known as object models. A COM object model is a parent object that holds a set of child objects. COM collections and enumerators are the glue that holds the parent and the children together. This chapter examines COM collections and enumerators and how they work together to build object models.
COM Collection and Enumeration Interfaces
Standard C++ Containers and Iterators
C++ programmers long ago learned to separate their collections into three pieces: the data itself, the container of the data, and an iterator for accessing the data. This separation is useful for building pieces separately from each other. The container’s job is to enable the user to affect the contents of the collection. The iterator’s job is to enable the user to access the contents of the container. And although the iterator implementation depends on how the container stores the data, the implementation details are hidden from the client of the container and the iterator. For example, imagine the following code for populating a container and then accessing it via an iterator:
1void main() {
2 // Populate the collection
3 vector<long> rgPrimes;
4 for (long n = 0; n != 1000; ++n) {
5 if (IsPrime(n)) rgPrimes.push_back(n);
6 }
7
8 // Count the number of items in the collection
9 cout << "Primes: " << rgPrimes.size() << endl;
10
11 // Iterate over the collection using sequential access
12 vector<long>::iterator begin = rgPrimes.begin();
13 vector<long>::iterator end = rgPrimes.end();
14 for (vector<long>::iterator it = begin; it != end; ++it) {
15 cout << *it << " ";
16 }
17 cout << endl;
18}
Because the container provides a well-known C++ interface, the client does not need to know the implementation details. In fact, C++ container classes are so uniform that this simple example would work just as well with a list or a deque as it does with a vector. Likewise, because the iterators that the container provides are uniform, the client doesn’t need to know the implementation details of the iterator.
For the client to enjoy these benefits, the container and the iterator have certain responsibilities. The responsibilities of the container include the following:
Can allow the user to manipulate the data. Most containers are of variable size and are populated by the client. However, some containers represent a fixed data set or a set of data that is calculated instead of stored.
Can allow the user to obtain the count of items. Containers have a
sizemethod for this purpose.Can allow random access. The
std::vectorclass allows this usingoperator[], whereas thestd::listclass does not.Must allow the user to access the data at least sequentially, if not randomly. C++ containers provide this facility by exposing iterators.
Likewise, the responsibilities of the iterator entail the following:
Must be capable of accessing the container’s data. That data might be in some shared spot (such as memory, file, or database) where the collection and iterator can both access the data. Alternatively, the iterator might have its own copy of the data. This would allow one client to access a snapshot of the data while another client modified the data using the container. Finally, the iterator could generate the data on demand – for example, by generating the next prime number.
The iterator must keep track of its current position in the collection of data. Every call to the iterator’s
operator++means to advance that position. Every call to the iterator’soperator*means to hand out the data at the current position.The iterator must be capable of indicating the end of the data to the client.
Although C++ containers and iterators are handy in your C++ code, neither is useful as a way of communicating data via a COM interface. Instead, we turn to the COM equivalent of containers and iterators: COM collections and enumerators.
COM Collections and Enumerators
A COM
collection is a COM object that holds a set of data and
allows the client to manipulate its contents via a COM interface.
In many ways, a COM collection is similar to a C++ container.
Unfortunately, IDL doesn’t support templates, so it’s impossible to
define a generic ICollection interface. Instead, COM
defines collections through coding conventions.
By convention, a COM collection interface takes a minimum form. This form is shown here, pretending that IDL supported templates:
1[ object, dual ]
2template <typename T>
3interface ICollection : IDispatch {
4 [propget]
5 HRESULT Count([out, retval] long* pnCount);
6
7 [id(DISPID_VALUE), propget]
8 HRESULT Item([in] long n, [out, retval] T* pnItem);
9
10 [id(DISPID_NEWENUM), propget]
11 HRESULT _NewEnum([out, retval] IUnknown** ppEnum);
12};
Several features about this interface are worth noting:
Although this minimal collection interface doesn’t show any methods for adding or removing elements from the collection, most collections include such methods.
Most collection interfaces are dual interfaces. An
IDispatch-based interface is required for some convenient language-mapping features that I discuss later.Most collection interfaces have a read-only
Countproperty that provides a count of the current elements in the collection. Not all collections can calculate a reliable count, however. Examples include a collection of all prime numbers and a collection of rows from a database query that hasn’t yet been completed.Most collection interfaces have a read-only
Itemproperty for random access to a specific element. The first parameter is the index of the element to access, which I’ve shown as along. It’s also common for this to be aVARIANTso that a number index or a string name can be used. If the index is a number, it is often 1-based, but the creator of the container can choose any indexing scheme desired. Furthermore, theItemproperty should be given the standard DISPIDDISPID_VALUE. This marks the property as the “default” property, which certain language mappings use to provide more convenient access. I show you how this works later.An interface is a collection interface when it exposes an enumerator via the read-only property
_NewEnum, which must be assigned the standard DISPIDDISPID_NEWENUM. Visual Basic uses this DISPID to implement itsFor-Eachsyntax, as I show you soon.
None of the methods specified earlier is actually required; you need to add only the methods you expect to support. However, it’s highly recommended to have all three. Without them, you’ve got a container with inaccessible contents, and you can’t even tell how many things are trapped in there.
A COM enumerator is to a COM collection as an iterator is to a container. The collection holds the data and allows the client to manipulate it, and the enumerator allows the client sequential access. However, instead of providing sequential access one element at a time, as with an iterator, an enumerator allows the client to decide how many elements it wants. This enables the client to balance the cost of round-trips with the memory requirements to handle more elements at once. A COM enumerator interface takes the following form (again, pretending that IDL supported templates):
1template <typename T>
2interface IEnum : IUnknown {
3 [local]
4 HRESULT Next([in] ULONG celt,
5 [out] T* rgelt,
6 [out] ULONG *pceltFetched);
7
8 [call_as(Next)] // Discussed later...
9 HRESULT RemoteNext([in] ULONG celt,
10 [out, size_is(celt),
11 length_is(*pceltFetched)] T* rgelt,
12 [out] ULONG *pceltFetched);
13
14 HRESULT Skip([in] ULONG celt);
15 HRESULT Reset();
16 HRESULT Clone([out] IEnum<T> **ppenum);
17}
A COM enumerator interface has the following properties:
The enumerator must be capable of accessing the data of the collection and maintaining a logical pointer to the next element to retrieve. All operations on an enumerator manage this logical pointer in some manner.
The
Nextmethod allows the client to decide how many elements to retrieve in a single round-trip. A result ofS_OKindicates that the exact number of elements requested by theceltparameter has been returned in thergeltarray. A result ofS_FALSEindicates that the end of the collection has been reached and that thepceltFetchedargument holds the number of elements actually retrieved. In addition to retrieving the elements, theNextmethod implementation must advance the logical pointer internally so that subsequent calls toNextretrieve additional data.The
Skipmethod moves the logical pointer but retrieves no data. Notice thatceltis an unsignedlong, so there is no skipping backward. You can think of an enumerator as modeling a single-linked list, although, of course, it can be implemented any number of ways.The
Resetmethod moves the logical pointer back to the beginning of the collection.The
Clonemethod returns a copy of the enumerator object. The copy refers to the same data (although it can have its own copy) and points to the same logical position in the collection. The combination ofSkip,Reset, andClonemakes up for the lack of aBackmethod.
Custom Collection and Enumerator Example
For example, let’s model a collection of prime numbers as a COM collection:
1[dual]
2interface IPrimeNumbers : IDispatch {
3 HRESULT CalcPrimes([in] long min, [in] long max);
4
5 [propget]
6 HRESULT Count([out, retval] long* pnCount);
7
8 [propget, id(DISPID_VALUE)]
9 HRESULT Item([in] long n, [out, retval] long* pnPrime);
10
11 [propget, id(DISPID_NEWENUM)] // Not quite right...
12 HRESULT _NewEnum([out, retval] IEnumPrimes** ppEnumPrimes);
13};
The corresponding enumerator looks like this:
1interface IEnumPrimes : IUnknown {
2 [local]
3 HRESULT Next([in] ULONG celt,
4 [out] long* rgelt,
5 [out] ULONG *pceltFetched);
6
7 [call_as(Next)]
8 HRESULT RemoteNext([in] ULONG celt,
9 [out, size_is(celt),
10 length_is(*pceltFetched)] long* rgelt,
11 [out] ULONG *pceltFetched);
12
13 HRESULT Skip([in] ULONG celt);
14 HRESULT Reset();
15 HRESULT Clone([out] IEnumPrimes **ppenum);
16};
Porting the previous C++ client to use the collection and enumerator looks like this:
1void main() {
2 CoInitialize(0);
3
4 CComPtr<IPrimeNumbers> spPrimes;
5 if (SUCCEEDED(spPrimes.CoCreateInstance(CLSID_PrimeNumbers))) {
6 // Populate the collection
7 HRESULT hr = spPrimes->CalcPrimes(0, 1000);
8
9 // Count the number of items in the collection
10 long nPrimes;
11 hr = spPrimes->get_Count(&nPrimes);
12 cout << "Primes: " << nPrimes << endl;
13
14 // Enumerate over the collection using sequential access
15 CComPtr<IEnumPrimes> spEnum;
16 hr = spPrimes->get__NewEnum(&spEnum);
17
18 const size_t PRIMES_CHUNK = 64;
19 long rgnPrimes[PRIMES_CHUNK];
20
21 do {
22 ULONG celtFetched;
23 hr = spEnum->Next(PRIMES_CHUNK, rgnPrimes, &celtFetched);
24 if (SUCCEEDED(hr)) {
25 if (hr == S_OK) celtFetched = PRIMES_CHUNK;
26 for (long* pn = &rgnPrimes[0];
27 pn != &rgnPrimes[celtFetched]; ++pn) {
28 cout << *pn << " ";
29 }
30 }
31 }
32 while (hr == S_OK);
33 cout << endl;
34
35 spPrimes.Release();
36 }
37
38 CoUninitialize();
39}
This client code asks the collection object to
populate itself via the CalcPrimes method instead of
adding each prime number one at a time. Of course, this procedure
reduces round-trips. The client further reduces round-trips when
retrieving the data in chunks of 64 elements. A chunk size of any
number greater than 1 reduces round-trips but increases the data
requirement of the client. Only profiling can tell you the right
number for each client/enumerator pair, but larger numbers are
preferred to reduce round-trips.
Dealing with the Enumerator local/call_as Oddity
One thing that’s rather odd about the client
side of enumeration is the pceltFetched parameter filled
by the Next method. The COM documentation is ambiguous,
but it boils down to this: When only a single element is requested,
the client doesn’t have to provide storage for the number of
elements fetched; that is, pceltFetched is allowed to be NULL. Normally, however, MIDL doesn’t allow an [out] parameter to be NULL. So, to support the
documented behavior for enumeration interfaces, all of them are
defined with two versions of the Next method. The [local] Next method is for use by the client and allows
the pceltFetched parameter to be NULL. The [call_as] RemoteNext method doesn’t allow the pceltFetched parameter to be NULL and is the
method that performs the marshaling. Although the MIDL compiler
implements the RemoteNext method, we have to implement Next manually because we’ve marked the Next method as [local]. In fact, we’re responsible for
implementing two versions of the Next method. One version
is called by the client and, in turn, calls the RemoteNext method implemented by the proxy. The other version is called by the
stub and calls the Next method implemented by the object. Figure 8.1 shows the progression of calls from client to
object through the proxy, the stub, and our custom code. The
canonical implementation is as follows:
1static HRESULT STDMETHODCALLTYPE
2IEnumPrimes_Next_Proxy(
3 IEnumPrimes * This, ULONG celt, long * rgelt,
4 ULONG* pceltFetched) {
5 ULONG cFetched;
6 if (!pceltFetched && celt != 1) return E_INVALIDARG;
7 return IEnumPrimes_RemoteNext_Proxy(This, celt, rgelt,
8 pceltFetched ? pceltFetched : &cFetched);
9}
10
11static HRESULT STDMETHODCALLTYPE
12IEnumPrimes_Next_Stub(IEnumPrimes * This, ULONG celt, long * rgelt,
13 ULONG* pceltFetched) {
14 HRESULT hr = This->lpVtbl->Next(This, celt, rgelt,
15 pceltFetched);
16 if (hr == S_OK && celt == 1) *pceltFetched = 1;
17 return hr;
18}
Figure 8.1. Call progression from client, through proxy and stub, to implementation of ``IEnumPrimes``
![[View full size image]](_static/images/08atl01_alt.jpg){kind=link}
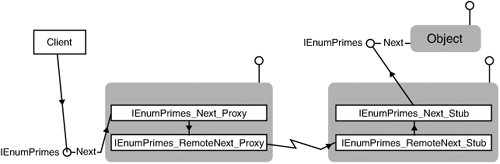
Every enumeration interface includes this code
in the proxy/stub implementation, including all the standard ones,
such as IEnumUnknown, IEnumString, and IEnumVARIANT. The only difference in implementation is the
name of the interface and the type of data being enumerated over
(as shown in the IEnumPrimes example in bold).
When you’re building the proxy/stub for your
project using the <project>PS project generated by
the ATL project template, and you have a custom enumeration interface, it’s your job to inject that
code into your proxy/stub. One way is to edit the <project>_p.c file, but if you were to recompile the
IDL, the implementation would be lost. Another way is to add
another .c file to the proxy/stub project. This is rather
unpleasant and requires that you remember to update this code every
time you edit the IDL file. The technique I prefer relies on macro
definitions used during the proxy-/stub-building process and makes
heavy use of the cpp_quote statement in IDL. [1] Whenever you have a custom enumeration interface, insert code like
this at the bottom of the IDL file, and all will be right with the
world (the bold code changes based on the enumeration
interface):
1cpp_quote("#ifdef __midl_proxy")
2cpp_quote("static HRESULT STDMETHODCALLTYPE")
3cpp_quote("IEnumPrimes_Next_Proxy")
4cpp_quote("(IEnumPrimes * This, ULONG celt,long * rgelt, ULONG* pceltFetched)")
5cpp_quote("{")
6cpp_quote(" ULONG cFetched;")
7cpp_quote(" if( !pceltFetched && celt != 1 ) return E_INVALIDARG;")
8cpp_quote(" return IEnumPrimes_RemoteNext_Proxy(This, celt, rgelt,")
9cpp_quote(" pceltFetched ? pceltFetched : &cFetched);")
10cpp_quote("}")
11cpp_quote("")
12cpp_quote("static HRESULT STDMETHODCALLTYPE")
13cpp_quote("IEnumPrimes_Next_Stub")
14cpp_quote("(IEnumPrimes* This, ULONG celt, long* rgelt, ULONG* pceltFetched)")
15cpp_quote("{")
16cpp_quote(" HRESULT hr = This->lpVtbl->Next(This, celt, rgelt,")
17cpp_quote(" pceltFetched);")
18cpp_quote(" if( hr == S_OK && celt == 1 ) *pceltFetched = 1;")
19cpp_quote(" return hr;")
20cpp_quote("}")
21cpp_quote("#endif // __midl_proxy")
All the code within the cpp_quote statements is deposited into the <project>.h file,
but because the __midl_proxy symbol is used, the code is
compiled only when building the proxy/stub.
An Enumeration Iterator
One other niggling problem with COM enumerators is
their ease of use or, rather, the lack thereof. It’s good that a
client has control of the number of elements to retrieve in a
single round-trip, but logically the client is still processing the
data one element at a time. This is obfuscated by the fact that
we’re using two loops instead of one. Of course, C++ being C++,
there’s no reason that a wrapper can’t be built to remove this
obfuscation. [2] Such a wrapper is included with the source
code examples for this book. It’s called the enum_iterator and is declared like this:
1#ifndef ENUM_CHUNK
2#define ENUM_CHUNK 64
3#endif
4
5template <typename EnumItf, const IID* pIIDEnumItf,
6 typename EnumType, typename CopyClass = _Copy<EnumType> >
7class enum_iterator {
8public:
9 enum_iterator(IUnknown* punkEnum = 0,
10 ULONG nChunk = ENUM_CHUNK);
11 enum_iterator(const enum_iterator& i);
12 ~enum_iterator();
13
14 enum_iterator& operator=(const enum_iterator& rhs);
15 bool operator!=(const enum_iterator& rhs);
16 bool operator==(const enum_iterator& rhs);
17
18 enum_iterator& operator++();
19 enum_iterator operator++(int);
20 EnumType& operator*();
21
22private:
23 ...
24};
The enum_iterator class provides a
standard C++-like forward iterator that wraps a COM enumerator. The
type of the enumeration interface and the type of data that it
enumerates are specified as template parameters. The buffer size is
passed, along with the pointer to the enumeration interface, as a
constructor argument. The first constructor allows for the common
use of forward iterators. Instead of asking a container for the
beginning and ending iterators, the beginning iterator is created
by passing a non-NULL enumeration interface pointer. The
end iterator is created by passing NULL. The copy
constructor is used when forming a looping statement. This iterator
simplifies the client enumeration code considerably:
1...
2// Enumerate over the collection using sequential access
3CComPtr<IEnumPrimes> spEnum;
4hr = spPrimes->get__NewEnum(&spEnum);
5
6// Using an C++-like forward iterator
7typedef enum_iterator<IEnumPrimes, &IID_IEnumPrimes, long>
8 primes_iterator;
9primes_iterator begin(spEnum, 64);
10primes_iterator end;
11for (primes_iterator it = begin; it != end; ++it) {
12 cout << *it << " ";
13}
14cout << endl;
15...
Or if you’d like to get a little more fancy, you
can use the enum_iterator with a function object and a
standard C++ algorithm, which helps you avoid writing the looping
code altogether:
1struct OutputPrime {
2 void operator()(const long& nPrime) {
3 cout << nPrime << " ";
4 }
5};
6
7 ...
8 // Using a standard C++ algorithm
9 typedef enum_iterator<IEnumPrimes, &IID_IEnumPrimes, long>
10 primes_iterator;
11 for_each(primes_iterator(spEnum, 64), primes_iterator(),
12 OutputPrime());
13 ...
This example might not be as clear to you as the looping example, but it warms the cockles of my C++ heart.
Enumeration and Visual Basic 6.0
In the discussion that follows and in all references to Visual Basic in this chapter, we talk specifically about Visual Basic 6.0, not the latest version, VB .NET. COM collections and enumerations evolved with VB6 in mind, so it’s insightful to examine client-side programming with VB6 and collections. VB .NET, of course, is an entirely different subject and squarely outside the scope of this book.
The C++ for_each algorithm might seem a
lot like the Visual Basic 6.0 (VB) For-Each statement, and
it is. The For-Each statement allows a VB programmer to
access each element in a collection, whether it’s an intrinsic
collection built into VB or a custom collection developed using
COM. Just as the for_each algorithm is implemented using
iterators, the For-Each syntax is implemented using a COM
enumerator; specifically, IEnumVARIANT. To support the For-Each syntax, the collection interface must be based on IDispatch and must have the _NewEnum property
marked with the special DISPID value DISPID_NEWENUM.
Because our prime number collection object exposes such a method,
you might be tempted to write the following code to exercise the For-Each statement:
1Private Sub Command1_Click()
2 Dim primes As IPrimeNumbers
3 Set primes = New PrimeNumbers
4 primes.CalcPrimes 0, 1000
5
6 MsgBox "Primes: " & primes.Count
7
8 Dim sPrimes As String
9 Dim prime As Variant
10
11 For Each prime In primes ' Calls Invoke(DISPID_NEWENUM)
12 sPrimes = sPrimes & prime & " "
13 Next prime
14
15 MsgBox sPrimes
16End Sub
When VB sees the For-Each statement, it
invokes the _NewEnum property, looking for an enumerator
that implements IEnumVARIANT. To support this use, our
prime number collection interface must change from exposing IEnumPrimes to exposing IEnumVARIANT. Here’s the
twist: The signature of the method is actually _NewEnum(IUnknown**), not _NewEnum(IEnumVARIANT**). VB takes the IUnknown* returned from _NewEnum and queries for IEnumVARIANT. It would’ve been nice for VB to avoid an
extra round-trip, but perhaps at one point, the VB team expected to
support other enumeration types.
Modifying IPrimeNumbers to support the VB For-Each syntax looks like this:
1[dual]
2interface IPrimeNumbers : IDispatch {
3 HRESULT CalcPrimes([in] long min, [in] long max);
4
5 [propget]
6 HRESULT Count([out, retval] long* pnCount);
7
8 [propget, id(DISPID_VALUE)]
9 HRESULT Item([in] long n, [out, retval] long* pnPrime);
10
11 [propget, id(DISPID_NEWENUM)]
12 HRESULT _NewEnum([out, retval] IUnknown** ppunkEnum);
13};
This brings the IPrimeNumbers interface
into line with the ICollection template form we showed you
earlier. In fact, it’s fair to say that the ICollection template form was defined to work with VB.
Note one important thing about VB’s For-Each statement. If your container contains objects
(your returned variants contain VT_UNKNOWN or VT_DISPATCH), the contained objects must implement the IDispatch interface. If they don’t, you’ll get an “item not an object” error
at runtime from VB 6.
The VB Subscript Operator
Using the Item method, a VB client can
access each individual item in the collection one at a time:
1...
2Dim i As Long
3For i = 1 To primes.Count
4 sPrimes = sPrimes & primes.Item(i) & " "
5Next i
6...
Because I marked the Item method with DISPID_VALUE, VB allows the following abbreviated syntax
that makes a collection seem like an array (if only for a
second):
1...
2Dim i As Long
3For i = 1 To primes.Count
4 sPrimes = sPrimes & primes(i) & " " ' Invoke(DISPID_VALUE)
5Next i
6...
Assigning a property the DISPID_VALUE dispatch identifier makes it the default property, as far as VB is
concerned. Using this syntax results in VB getting the default
property – that is, calling Invoke with DISPID_VALUE. However, because we’re dealing with array
syntax in VB, we have two problems. The first is knowing where to
start the index1 or 0? A majority of existing code suggests making
collections 1-based, but only a slight majority. As a collection
implementer, you get to choose. As a collection user, you get to
guess. In general, if you anticipate a larger number of VB clients
for your collection, choose 1-based; and whatever you do, please document the decision.
The other concern with using array-style access
is round-trips. Using the Item property puts us smack dab
in the middle of what we’re trying to avoid by using enumerators:
one round-trip per data element. If you think that using the For-Each statement and, therefore, enumerators under VB
solves both these problems, you’re half right. Unfortunately,
Visual Basic 6.0 continues to access elements one at a time, even
though it’s using IEnumVARIANT::Next and is perfectly
capable of providing a larger buffer. However, using the For-Each syntax does allow you to disregard whether the Item method is 1-based or 0-based.
The Server Side of Enumeration
Because the semantics of enumeration interfaces are loose, you are free to implement them however you like. The data can be pulled from an array, a file, a database result set, or wherever it is stored. Even better, you might want to calculate the data on demand, saving yourself calculations and storage for elements in which the client isn’t interested. Either way, if you’re doing it by hand, you have some COM grunge code to write. Or, if you like, ATL is there to help write that grunge code.
Enumerating Arrays
CComEnum
Because enumeration interfaces are all the same
except for the actual data being enumerated, their implementation
can be standardized, given a couple assumptions. Depending on how
you’ve stored your data, you can use one of two ATL enumeration
interface classes. The most flexible implementation class enables
you to provide your data in a standard C++-like collection. This is
called CComEnumOnSTL (discussed later). The simplest
implementation assumes that you’ve stored your data as an array.
It’s called CComEnum, and the complete implementation is
as follows:
1template <class Base, const IID* piid, class T, class Copy,
2 class ThreadModel = CComObjectThreadModel>
3class ATL_NO_VTABLE CComEnum :
4 public CComEnumImpl<Base, piid, T, Copy>,
5 public CComObjectRootEx< ThreadModel > {
6public:
7 typedef CComEnum<Base, piid, T, Copy > _CComEnum;
8 typedef CComEnumImpl<Base, piid, T, Copy > _CComEnumBase;
9 BEGIN_COM_MAP(_CComEnum)
10 COM_INTERFACE_ENTRY_IID(*piid, _CComEnumBase)
11 END_COM_MAP()
12};
Although this implementation consists of only a few lines of code, there’s quite a lot going on here. The template arguments are as follows:
Baseis the enumeration interface to be implemented – for example,IEnumPrimes.piidis a pointer to the interface being implemented – for example,&IID_IEnumPrimes.Tis the type of data being enumerated – for example,long.Copyis the class responsible for copying the data into the client’s buffer as part of the implementation ofNext. It can also be used to cache a private copy of the data in the enumerator to guard against simultaneous access and manipulation.ThreadModeldescribes just how thread safe this enumerator needs to be. When you specify nothing, it uses the dominant threading model for objects, as described in Chapter 4, “Objects in ATL.” Of course, because a COM enumerator is a COM object like any other, it requires an implementation ofIUnknown. Toward that end,CComEnumderives fromCComObjectRootEx. You’ll see later that I further deriveCComObjectfromCComEnumto fill in thevtblproperly.
Really, CComEnum is present simply to
bring CComObjectRootEx together with CComEnumImpl, the base class that actually implements Next, Skip, Reset, and Clone.
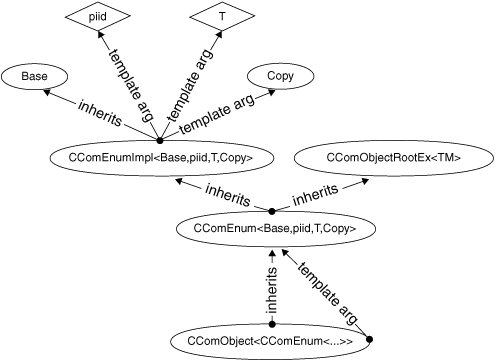
Figure 8.2 shows how these
classes fit together.
Figure 8.2. The ``CComEnum`` inheritance hierarchy
Copy Policy Classes
The fundamental job of the
enumerator is to copy the collection’s data into the buffer that
the client provides. If the data being enumerated is a pointer or a
structure that contains pointers, a simple memcpy or
assignment will not do the trick. Instead, the client needs its own
deep copy of each element, which it can release when it has
finished with it. Toward that end, ATL enumerators use a class
called a copy policy class, often
just called a copy policy, to
scope static methods for dealing with deep-copy semantics. The
static methods of a copy policy are like the Increment and Decrement methods of the threading model classes, except
that instead of incrementing and decrementing a long, copy
policies know how to initialize, copy, and destroy data. For simple
types, ATL provides a template copy policy class:
1template <class T>
2class _Copy{
3public:
4 static HRESULT copy(T* p1, const T* p2) {
5 Checked::memcpy_s(p1, sizeof(T), p2, sizeof(T));
6 return S_OK;
7 }
8 static void init(T*) {}
9 static void destroy(T*) {}
10};
Given an array of a simple type (such as long), this template works just fine:
1HRESULT CopyRange(long* dest, long* src, size_t count) {
2 for (size_t i = 0; i != count; ++i) {
3 HRESULT hr = _Copy<long>::copy(&dest[i], &src[i]);
4 if( FAILED(hr) ) {
5 while( i > 0 )_Copy<long>::destroy(&dest[--i]);
6 return hr;
7 }
8 }
9 return S_OK;
10}
However, given something with trickier
semantics, such as a VARIANT or an OLESTR,
memcpy is too shallow. For the four most commonly
enumerated data types, ATL provides specializations of the _Copy template:
1template<> class _Copy<VARIANT>;
2template<> class _Copy<LPOLESTR>;
3template<> class _Copy<OLEVERB>
4template<> class _Copy<CONNECTDATA>;
For example, the copy policy for VARIANT s looks like this:
1template<> class _Copy<VARIANT> {
2public:
3 static HRESULT copy(VARIANT* p1, const VARIANT* p2) {
4 p1->vt = VT_EMPTY;
5 return VariantCopy(p1, const_cast<VARIANT*>(p2));
6 }
7 static void init(VARIANT* p) {p->vt = VT_EMPTY;}
8 static void destroy(VARIANT* p) {VariantClear(p);}
9};
If you’re dealing with interface pointers,
again, the _Copy template won’t do, but building your own
specialization for each interface you want to copy is a bit arduous. For interfaces,
ATL provides the _CopyInterface copy policy class
parameterized on the type of interface you’re managing:
1template <class T> class _CopyInterface {
2public:
3 static HRESULT copy(T** p1, T** p2) {
4 ATLENSURE(p1 != NULL && p2 != NULL);
5 *p1 = *p2;
6 if (*p1)
7 (*p1)->AddRef();
8 return S_OK;
9 }
10 static void init(T** ) {}
11 static void destroy(T** p) {if (*p) (*p)->Release();}
12};
Using copy policies, we now have a generic way to initialize, copy, and delete any kind of data, making it easy to build a generic and safe duplication routine:
1template <typename T, typename Copy>
2HRESULT CopyRange(T* dest, T* src, size_t count) {
3 for (size_t i = 0; i != count; ++i) {
4 HRESULT hr = Copy::copy(&dest[i], &src[i]);
5 if( FAILED(hr) ) {
6 while( i > 0 ) Copy::destroy(&dest[--i]);
7 return hr;
8 }
9 }
10 return S_OK;
11}
CComEnumImpl’s implementation of the Next method uses the copy policy passed as the template
parameter to initialize the client’s buffer and fill it with data
from the collection, much like our sample CopyRange routine. However, before we jump right into the Next method, let’s see how CComEnumImpl does its job.
Enumerating Standard C++ Collections
IEnumOnSTLImpl
The base class of CComEnumOnSTL,
IEnumOnSTLImpl, uses the standard C++-like collection
passed as the CollType parameter to implement the Next, Skip, Reset, and Clone methods. The following is the declaration of IEnumOnSTLImpl:
1template <class Base, const IID* piid, class T,
2 class Copy, class CollType>
3class ATL_NO_VTABLE IEnumOnSTLImpl : public Base {
4public:
5 HRESULT Init(IUnknown *pUnkForRelease, CollType& collection);
6
7 STDMETHOD(Next)(ULONG celt, T* rgelt, ULONG* pceltFetched);
8 STDMETHOD(Skip)(ULONG celt);
9 STDMETHOD(Reset)(void);
10 STDMETHOD(Clone)(Base** ppEnum);
11
12// Data
13 CComPtr<IUnknown> m_spUnk;
14 CollType* m_pcollection;
15 typename CollType::const_iterator m_iter;
16};
As with CComEnumImpl,
IEnumOnSTLImpl keeps an m_spUnk pointer. However,
unlike CComEnumImpl, the m_spUnk pointer should
never be NULL and, therefore, the pUnkForRelease parameter to Init should never be NULL. Notice
that IEnumOnSTLImpl keeps no m_dwFlags member
data. It has no option for copying the data from the collection.
Instead, it needs to ensure that the collection holding the data
outlives the enumerator. Every call to Init assumes the
equivalent of the CComEnum’s AtlFlagNoCopy flag.
Although this is more efficient than AtlFlagCopy or the
manual copying required for AtlFlagTakeOwnership, if the
collection changes while it’s being enumerated, the behavior is
undefined. If you need ATL’s C++-based enumerator to have its own
copy of the data, you must wrap a copy of the data in its own COM
object, a technique I show you later.
On-Demand Data Conversion
The implementations of the Next,
Skip, Reset, and Clone methods using a
standard C++ collection are almost identical to those of the CComEnumImpl class. The single significant difference is a
nifty loophole in the IEnumOnSTLImpl’s Next method. The CComEnumImpl class ties the data type being
enumerated to the data type held in the array of the enumerator.
However, IEnumOnSTLImpl has no such limitation. Look at
this snippet from IEnumOnSTLImpl’s Next method:
1template <class Base, const IID* piid, class T, class Copy,
2 class CollType>
3STDMETHODIMP
4IEnumOnSTLImpl<Base, piid, T, Copy, CollType>::Next(
5 ULONG celt, T* rgelt, ULONG* pceltFetched) {
6 ...
7 T* pelt = rgelt;
8 while (SUCCEEDED(hr) && m_iter != m_pcollection->end() &&
9 nActual < celt) {
10 hr = Copy::copy(pelt, &*m_iter);
11 ...
12 }
13 ...
14 return hr;
15}
The template parameters allow the type of the *pelt to be different from the type of the &*m_iter. In other words, the type of data that the
collection holds can be different from the type of data that the
client receives in the call to Next. This means that the
copy policy class must still be capable of initializing and
destroying the data of the type being enumerated, but the copy
operation could actually be hijacked to convert from one data type
to another.
Imagine the following copy policy:
1struct _CopyVariantFromLong {
2 static HRESULT copy(VARIANT* p1, long* p2) {
3 p1->vt = VT_I4;
4 p1->lVal = *p2;
5 return S_OK;
6 }
7 static void init(VARIANT* p) { VariantInit(p); }
8 static void destroy(VARIANT* p) { VariantClear(p); }
9};
If the collection held long s but the
enumerator exposed VARIANT s, the _CopyVariantFromLong copy policy could be used to convert
that data on demand. For example, if the prime number collection
object was keeping a collection of long s, the following
code would create an enumerator that could convert from long to VARIANT, as appropriate, during the
client’s Next call:
1STDMETHODIMP CPrimeNumbers::get__NewEnum(IUnknown** ppunkEnum) {
2 *ppunkEnum = 0;
3
4 typedef CComEnumOnSTL<IEnumVARIANT, &IID_IEnumVARIANT, VARIANT,
5 _CopyVariantFromLong, vector<long> >
6 CComEnumVariantOnVectorOfLongs;
7
8 CComObject<CComEnumVariantOnVectorOfLongs>* pe = 0;
9 ... // The rest is the same!
10}
The only difference between this example and the
previous one is the enumerator type definition. Instead of building
it using a vector of VARIANT s, we build it using a vector
of long s. Because the data type of the collection is
different from the data type of the enumerator, we simply provide a
copy policy class whose copy method converts
appropriately. This is an especially useful technique for mapping
between whatever is the most convenient type to hold in your
collection object and VARIANT s to support the VB For-Each syntax.
On-Demand Data Calculation
CComEnum requires initialization with an
array of data that is already calculated. CComEnumOnSTL,
on the other hand, accesses the data by calling member functions on
objects that we provide. Therefore, calculating data on demand is a
matter of providing implementations of the member functions that
perform the calculations instead of accessing precalculated
results.
For example, there’s no reason the collection of
prime numbers needs to precalculate all the results and store them.
Instead, we need a standard C++-like container that looks like what CComEnumOnSTL needs (as I showed you before) but
calculates the next prime number on demand. This container has two
responsibilities. The first is to keep track of the range of values
to iterate over. The second responsibility is to expose an iterator
for both the beginning and one past the ending of the data. The
beginning and ending iterator must be exposed via begin and end methods, and each must return a value of type const_iterator, a type nested inside the class.
The PrimesContainer class lives up to both these
responsibilities:
1class PrimesContainer {
2public:
3 class const_iterator; // Forward declaration
4
5 PrimesContainer() : m_min(0), m_max(0) {}
6
7 // For IPrimeNumbers::CalcPrimes
8 void SetRange(long min, long max)
9 { m_min = min; m_max = max; }
10
11 // For IPrimeNumbers::get_Count
12 size_t size()
13 { return CountPrimes(m_min, m_max); }
14
15 // For IPrimeNumbers::get_Item
16 long operator[](size_t i)
17 { return NthPrime(i + 1, m_min, m_max); }
18
19 // The rest is for CComEnumOnSTL
20 const_iterator begin() const
21 { return const_iterator(m_min, m_max); }
22
23 const_iterator end() const
24 { return const_iterator(); }
25
26 class const_iterator {...};
27private:
28 long m_min, m_max;
29};
Notice that, in addition to supporting the
minimum interface required by the implementation of CComEnumOnSTL, the PrimesContainer class provides
a SetRange method for managing the range of prime numbers,
a size method for counting the prime numbers in the range,
and an operator[] method for extracting items in a
random-access fashion. These methods make the PrimesContainer class suitable for implementing the IPrimeNumbers interface.
1class ATL_NO_VTABLE CPrimeNumbers :
2 public CComObjectRootEx<CComSingleThreadModel>,
3 public CComCoClass<CPrimeNumbers, &CLSID_PrimeNumbers>,
4 public IDispatchImpl<IPrimeNumbers, &IID_IPrimeNumbers> {
5public:
6...
7// IPrimeNumbers
8public:
9 STDMETHODIMP CalcPrimes(long min, long max)
10 { m_rgPrimes.SetRange(min, max); return S_OK; }
11
12 STDMETHODIMP get_Count(long* pnCount)
13 { *pnCount = m_rgPrimes.size(); return S_OK; }
14
15 STDMETHODIMP get_Item(long n, long* pnPrime) {
16 if (n < 1 || n > m_rgPrimes.size() ) return E_INVALIDARG;
17 *pnPrime = m_rgPrimes[n-1];
18 return S_OK;
19 }
20
21 STDMETHODIMP get__NewEnum(IUnknown** ppunkEnum) {
22 *ppunkEnum = NULL;
23
24 typedef CComEnumOnSTL<IEnumVARIANT, &IID_IEnumVARIANT,
25 VARIANT, _CopyVariantFromLong, PrimesContainer >
26 CComEnumVariantOnPrimesContainer;
27
28 CComObject<CComEnumVariantOnPrimesContainer>* pe = NULL;
29 HRESULT hr = pe->CreateInstance(&pe);
30 if (SUCCEEDED(hr)) {
31 pe->AddRef();
32
33 hr = pe->Init(this->GetUnknown(), m_rgPrimes);
34 if (SUCCEEDED(hr)) {
35 hr = pe->QueryInterface(ppunkEnum);
36 }
37 pe->Release();
38 }
39 return hr;
40 }
41
42 private:
43 PrimesContainer m_rgPrimes;
44};
In fact, this code is nearly identical to the code I’ve already shown you. The difference is that, instead of using a container that already has a precalculated set of values, we have one that knows how to calculate them on demand. Specifically, the iterator does the magic:
1class PrimesContainer {
2...
3 const_iterator begin() const
4 { return const_iterator(m_min, m_max); }
5
6 const_iterator end() const
7 { return iterator(); }
8
9class const_iterator {
10 public:
11 const_iterator (long min = -1, long max = -1)
12 : m_max(max), m_next(NthPrime(1, min, max))
13 { if( m_next == -1 ) m_max = -1; } // Match end()
14
15 bool operator!=(const const_iterator& rhs)
16 { return (m_next != rhs.m_next || m_max != rhs.m_max); }
17
18 const long& operator*()
19 { return m_next; }
20
21 const_iterator operator++(int) {
22 const_iterator it(m_next, m_max);
23 m_next = NthPrime(1, m_next + 1, m_max);
24 if( m_next == -1 ) m_max = -1; // Match end()
25 return it;
26 }
27
28 private:
29 long m_next, m_max;
30 };
31...
32};
The key to understanding the iterator is
understanding how CComEnumOnSTL uses it. CComEnumOnSTL keeps a pointer to the collection, called m_pcollection, and an iterator, called m_iter,
that marks the current position in the container. The m_iter data member is initialized when the enumerator is
constructed or when Reset is called to the result of m_pcollection->begin(). The implementation of begin constructs an iterator that uses the range of
possible prime numbers to cache the next prime number and the
maximum number to check. As the container is iterated, the next
prime number is calculated one ahead of the request. For every
element in the container, the following sequence is performed:
m_pcollection->end()constructs an iterator that marks the end of the data. This, in turn, creates an iterator with1for each ofm_min,m_max, andm_next. Special member data values are common for constructing an iterator that marks the end of the data.operator!=compares the current iterator with the ending iterator.operator*pulls out the prime number at the current location of the iterator.The postfix
operator++calculates the next prime number. If there are no more prime numbers,m_min,m_max, andm_nextare each set to1to indicate the end of the data. The next time through the loop, the comparison with the ending iterator succeeds andCComEnumOnSTLdetects that it has reached the end of the collection.
You can see this behavior by looking at the main
loop in the CComEnumOnSTLImpl::Next implementation:
1template <class Base, const IID* piid, class T, class Copy,
2 class CollType>
3STDMETHODIMP
4IEnumOnSTLImpl<Base, piid, T, Copy, CollType>::Next(
5 ULONG celt, T* rgelt, ULONG* pceltFetched) {
6 ...
7
8 ULONG nActual = 0;
9 HRESULT hr = S_OK;
10 T* pelt = rgelt;
11 while (SUCCEEDED(hr) &&
12 m_iter != m_pcollection->end() && nActual < celt) {
13 hr = Copy::copy(pelt, &*m_iter);
14 if (FAILED(hr)) {
15 while (rgelt < pelt) Copy::destroy(rgelt++);
16 nActual = 0;
17 }
18 else {
19 pelt++;
20 m_iter++;
21 nActual++;
22 }
23 }
24 ...
25 return hr;
26}
If you find the occasion to calculate data on
demand using a custom container and iterator pair, yours will be
called in the same sequence. This gives you an opportunity to
calculate data appropriately for your data set – for example, lines in
a file, records in a database, bytes from a socket. Why go to all
this trouble to calculate data on demand? Efficiency in both time
and space. There are 9,592 prime numbers between 0 and 100,000.
Precalculating and storing the primes as long s costs
nearly 38 KB. Worse, the client must wait for all primes to be
calculated in this range, even if it never gets around to
enumerating them all. On the other hand, calculating them on demand
requires the m_min and m_max members of the
container and the m_next and m_max members of the
current iterator. That’s 16 bytes no matter how many prime numbers
we’d like to calculate, and the cost of calculating them is
realized only when the client requests the next chunk. [4]
Collections
ICollectionOnSTLImpl
In addition to parameterized implementations of
enumeration interfaces, ATL provides parameterized implementations
of collection interfaces, assuming that you’re willing to keep your
data in a standard C++-like container. The implementation is
provided by the ICollectionOnSTLImpl class:
1template <class T, class CollType, class ItemType,
2 class CopyItem, class EnumType>
3class ICollectionOnSTLImpl: public T {
4public:
5 STDMETHOD(get_Count)(long* pcount);
6 STDMETHOD(get_Item)(long Index, ItemType* pvar);
7 STDMETHOD(get__NewEnum)(IUnknown** ppUnk);
8
9 CollType m_coll;
10};
The ICollectionOnSTLImpl class provides an implementation of
the three standard collection properties much like what I showed
you earlier. The chief difference is that the container is managed
for you in the m_coll member data of the ICollectionOnSTLImpl class. That means that you can’t
provide a copy of the data to the enumerators, but you can still
use a collection that calculates on demand and you can still
convert from a convenient type to the type required by the
enumerator exposed from get__NewEnum. This is because,
although you get to decide the type of the container in a template
parameter, you’re no longer implementing get__NewEnum.
The template parameters of ICollectionOnSTLImpl are as follows:
The
Tparameter indicates the base class – For example,IDispatchImpl-<IPrimeNumbersand&IID_IPrimeNumbers>.ICollectionOnSTLImplprovides the implementation of the standard three properties of this base class, but the deriving class is responsible for the rest.The
CollTypeparameter indicates the type of container to keep – for example,vector<long>orPrimesContainer.The
ItemTypeparameter indicates the type of data exposed from the iterator of the collection – for example,long.The
CopyItemparameter indicates the type of the copy policy class. This copy policy is used only in the implementation of theget_Itemmethod. The copy policy should be capable of copying from a container that holds items of typeItemTypeto a single[out]parameter of typeItemType. If you were managing a container oflong numbers, theCopyItemtype would be_Copy<long>.The
EnumTypeparameter indicates the type of the enumeration-implementation class. This enumeration must be capable of enumerating over a container just likeCComEnumOnSTL. An exampleEnumTypeparameter isCComEnumOnSTLImpl<IEnumVARIANT, &IID_IEnumVARIANT, VARIANT, _Copy<VARIANT>, vector<VARIANT> >.
ICollectionOnSTLImpl Usage
The best way to understand the ICollectionOnSTLImpl class is to see it in action. The
first C++based implementation of the IPrimesCollection standard collection interface assumed that we wanted to manage a
precalculated container of VARIANT s. This can be done
using ICollectionOnSTLImpl:
1// Needed for implementation of get_Item.
2// Converts the storage type (VARIANT) to the item type (long).
3struct _CopyLongFromVariant {
4 static HRESULT copy(long* p1, VARIANT* p2) {
5 if (p2->vt == VT_I4) {
6 *p1 = p2->lVal;
7 return S_OK;
8 }
9 else {
10 VARIANT var;
11 HRESULT hr = VariantChangeType(&var, p2, 0, VT_I4);
12 if (SUCCEEDED(hr)) *p1 = var.lVal;
13 return hr;
14 }
15 }
16
17 static void init(long* p) { }
18 static void destroy(long* p) { }
19};
20
21// Needed for implementation of IDispatch methods
22typedef IDispatchImpl<IPrimeNumbers, &IID_IPrimeNumbers>
23 IPrimeNumbersDualImpl;
24
25// Needed for implementation of get__NewEnum method
26typedef CComEnumOnSTL<IEnumVARIANT, &IID_IEnumVARIANT, VARIANT,
27 _Copy<VARIANT>, vector<VARIANT> > ComEnumVariantOnVector;
28
29// Needed for implementation of standard collection methods
30typedef ICollectionOnSTLImpl<IPrimeNumbersDualImpl,
31 vector<VARIANT>, long, _CopyLongFromVariant,
32 CComEnumVariantOnVector>
33 IPrimeNumbersCollImpl;
34
35class ATL_NO_VTABLE CPrimeNumbers :
36 public CComObjectRootEx<CComSingleThreadModel>,
37 public CComCoClass<CPrimeNumbers, &CLSID_PrimeNumbers>,
38 public IPrimeNumbersCollImpl
39{
40public:
41...
42// IPrimeNumbers
43public:
44 STDMETHODIMP CalcPrimes(long min, long max) {
45 m_coll.clear();
46 for (long n = min; n <= max; ++n) {
47 if (IsPrime(n)) {
48 VARIANT var = {VT_I4};
49 var.lVal = n;
50 m_coll.push_back(var);
51 }
52 }
53
54 return S_OK;
55 }
56};
If we wanted to precalculate the prime numbers
but keep them as a vector of long numbers, this is how
we’d use ICollectionOnSTLImpl:
1// Needed for implementation of get__NewEnum.
2// Converts the storage type (long) to the
3// enumeration type (VARIANT).
4struct _CopyVariantFromLong {
5 static HRESULT copy(VARIANT* p1, long* p2) {
6 if (p1->vt == VT_I4) {
7 *p2 = p1->lVal;
8 return S_OK;
9 }
10 else {
11 VARIANT var;
12 HRESULT hr = VariantChangeType(&var, p1, 0, VT_I4);
13 if( SUCCEEDED(hr) ) *p2 = var.lVal;
14 return hr;
15 }
16 }
17
18 static void init(VARAINT* p) { ::VariantInit(p); }
19 static void destroy(VARIANT* p) { ::VariantClear(p); }
20};
21
22// Needed for implementation of IDispatch methods
23typedef IDispatchImpl<IPrimeNumbers, &IID_IPrimeNumbers>
24 IPrimeNumbersDualImpl;
25
26// Needed for implementation of get__NewEnum method
27typedef CComEnumOnSTL<IEnumVARIANT, &IID_IEnumVARIANT, VARIANT,
28 _CopyVariantFromLong, vector<long> >
29 CComEnumVariantOnVectorOfLongs;
30
31// Needed for implementation of standard collection methods
32typedef ICollectionOnSTLImpl<IPrimeNumbersDualImpl,
33 vector<long>, long, _Copy<long>,
34 CComEnumVariantOnVectorOfLongs>
35 IPrimeNumbersCollImpl;
36
37class ATL_NO_VTABLE CPrimeNumbers :
38 public CComObjectRootEx<CComSingleThreadModel>,
39 public CComCoClass<CPrimeNumbers, &CLSID_PrimeNumbers>,
40 public IPrimeNumbersCollImpl {
41public:
42...
43// IPrimeNumbers
44public:
45 STDMETHODIMP CalcPrimes(long min, long max) {
46 m_coll.clear();
47 for (long n = min; n <= max; ++n) {
48 if (IsPrime(n)) {
49 m_coll.push_back(n);
50 }
51 }
52
53 return S_OK;
54 }
55};
Finally, if we wanted to have the prime numbers
calculated on demand and exposed as long numbers, we’d use ICollectionOnSTLImpl:
1// Calculates prime numbers on demand
2class PrimesContainer;
3
4// Needed for implementation of get__NewEnum.
5// Converts the storage type (long) to the item type (VARIANT).
6struct _CopyVariantFromLong;
7
8// Needed for implementation of IDispatch methods
9typedef IDispatchImpl<IPrimeNumbers, &IID_IPrimeNumbers>
10 IPrimeNumbersDualImpl;
11
12// Needed for implementation of get__NewEnum method
13typedef CComEnumOnSTL<IEnumVARIANT, &IID_IEnumVARIANT, VARIANT,
14 _CopyVariantFromLong, PrimesContainer>
15 CComEnumVariantOnPrimesContainer;
16
17// Needed for implementation of standard collection methods
18typedef ICollectionOnSTLImpl<IPrimeNumbersDualImpl,
19 PrimesContainer, long, _Copy<long>,
20 CComEnumVariantOnPrimesContainer>
21 IPrimeNumbersCollImpl;
22
23class ATL_NO_VTABLE CPrimeNumbers :
24 public CComObjectRootEx<CComSingleThreadModel>,
25 public CComCoClass<CPrimeNumbers, &CLSID_PrimeNumbers>,
26 public IPrimeNumbersCollImpl {
27public:
28...
29// IPrimeNumbers
30public:
31 STDMETHODIMP CalcPrimes(long min, long max)
32 { m_coll.SetRange(min, max); }
33};
Jim
Springfield, the father of ATL, says “ICollectionOnSTLImpl is not for the faint of heart.” He’s absolutely right. It provides
a lot of flexibility, but at the expense of complexity. Still, when
you’ve mastered the complexity, as with any good class library, you
can get a lot done with very little code.
Standard C++ Collections of ATL Data Types
If you’re a fan of the standard C++ library, you
might find yourself wanting to keep some of ATL’s smart types (such
as CComBSTR, CComVariant, CComPtr, and CComQIPtr) in a standard C++ container. Many containers
have a requirement concerning the elements they hold that makes
this difficult for ATL smart types: operator& must
return an address to an instance of the type being held. However,
all the smart types except CComVariant overload operator& to return the address of the internal
data:
1BSTR* CComBSTR:operator&() { return &m_str; }
2T** CComPtr::operator&() { ATLASSERT(p==NULL); return &p; }
3T** CComQIPtr::operator&() { ATLASSERT(p==NULL); return &p; }
These overloads mean that CComBSTR,
CComPtr, and CComQIPtr cannot be used in many C++
containers or with standard C++ algorithms with the same
requirement.The classic workaround for
this problem is to maintain a container of a type that holds the
ATL smart type but that doesn’t overload operator&.
ATL provides the CAdapt class for this purpose.
ATL Smart Type Adapter
The CAdapt class is provided for the
sole purpose of wrapping ATL smart types for use in C++ containers.
It’s parameterized to accept any of the current or future such
types:
1template <class T> class CAdapt {
2public:
3 CAdapt() { }
4
5 CAdapt(__in const T& rSrc) :
6 m_T( rSrc )
7 { }
8
9 CAdapt(__in const CAdapt& rSrCA) :
10 m_T( rSrCA.m_T )
11 { }
12
13 CAdapt& operator=(__in const T& rSrc)
14 { m_T = rSrc; return *this; }
15
16 bool operator<(__in const T& rSrc) const
17 { return m_T < rSrc; }
18
19 bool operator==(__in const T& rSrc) const
20 { return m_T == rSrc; }
21
22 operator T&()
23 { return m_T; }
24
25 operator const T&() const
26 { return m_T; }
27
28T m_T;
29};
Notice that CAdapt does not have an operator&, so it works just fine for C++ containers
and collections. Also notice that the real data is held in a public
member variable called m_T. Typical usage requires using
either this data member or a static_cast to obtain the
underlying data.
CAdapt Usage
For example, imagine that you want to expose
prime numbers as words instead of digits. Of course, you’d like the
collection to support multiple languages, so you want to expose the
strings in Unicode. Also, you’d like to support type-challenged COM
mappings, so the strings have to be BSTR s. These
requirements suggest the following interface:
1[ object, dual]
2interface IPrimeNumberWords : IDispatch {
3 HRESULT CalcPrimes([in] long min, [in] long max);
4
5 [propget]
6 HRESULT Count([out, retval] long* pnCount);
7
8 [propget, id(DISPID_VALUE)]
9 HRESULT Item([in] long n,
10 [out, retval] BSTR* pbstrPrimeWord);
11
12 [propget, id(DISPID_NEWENUM)]
13 HRESULT _NewEnum([out, retval] IUnknown** ppunkEnum);
14};
Notice that the Item property exposes
the prime number as a string, not a number. Also keep in mind that
although the signature of _NewEnum is unchanged, we will
be returning VARIANT s to the client that contain BSTR s, not long numbers.
Because we’re dealing with one of the COM data
types that’s inconvenient for C++ programmers, BSTR s, we’d
like to use the CComBSTR smart data type described in Chapter 3, “ATL Smart
Types.” The compiler doesn’t complain if we use a data member like
this to maintain the data:
1vector<CComBSTR> m_rgPrimes;
Unfortunately, depending on what we do with the
vector, some obscure runtime errors can result because of CComBSTR’s overloaded operator&. Instead, we
use CAdapt to hold the data:
1vector< CAdapt<CComBSTR> > m_rgPrimes;
Of course, because we’re using strings, our method implementations change. To calculate the data, we change the prime numbers to strings:
1STDMETHODIMP CPrimeNumberWords::CalcPrimes(long min, long max) {
2 while (min <= max) {
3 if (IsPrime(min)) {
4 char sz[64];
5 CComBSTR bstr = NumWord(min, sz);
6 m_rgPrimes.push_back(bstr);
7 }
8 ++min;
9 }
10
11 return S_OK;
12}
Notice how we can simply push a CComBSTR onto the vector. The compiler uses the CAdapt<CComBSTR> constructor that takes a const CComBSTR& to construct the appropriate object for the
vector to manage. The get_Count method doesn’t change, but
the get_Item method does:
1STDMETHODIMP CPrimeNumberWords::get_Item(long n,
2 BSTR* pbstrPrimeWord) {
3 if (n < 1 || n > m_rgPrimes.size()) return E_INVALIDARG;
4
5 CComBSTR& bstr = m_rgPrimes[n-1].m_T;
6 return bstr.CopyTo(pbstrPrimeWord);
7}
Notice that we’re reaching into the vector and
pulling out the appropriate element. Again, remember that the type
of element we’re holding is CAdapt<CComBSTR>, so
I’ve used the m_T element to access the CComBSTR data inside. However, because the CAdapt<CComBSTR> class has an implicit cast operator to CComBSTR&,
using the m_T member explicitly is not necessary.
Finally, the get__NewEnum method must
also change. Remember that we’re implementing IEnumVARIANT, but instead of holding long numbers, we’re holding BSTR s. Therefore, the on-demand
data conversion must convert between a CAdapt<CComBSTR> (the data type held in the
container) to a VARIANT holding a BSTR. This can
be accomplished with another custom copy policy class:
1struct _CopyVariantFromAdaptBstr {
2 static HRESULT copy(VARIANT* p1, CAdapt<CComBSTR>* p2) {
3 p1->vt = VT_BSTR;
4 p1->bstrVal = p2->m_T.Copy();
5 return (p1->bstrVal ? S_OK : E_OUTOFMEMORY);
6 }
7 static void init(VARIANT* p) { VariantInit(p); }
8 static void destroy(VARIANT* p) { VariantClear(p); }
9};
The corresponding enumeration type definition looks like this:
1typedef CComEnumOnSTL<IEnumVARIANT, &IID_IEnumVARIANT, VARIANT,
2 _CopyVariantFromAdaptBstr,
3 vector< CAdapt<CComBSTR> > >
4 CComEnumVariantOnVectorOfAdaptBstr;
Using these two type definitions, implementing get__NewEnum looks much like it always does:
1STDMETHODIMP CPrimeNumberWords::get__NewEnum(
2 IUnknown** ppunkEnum) {
3 *ppunkEnum = 0;
4
5 CComObject<CComEnumVariantOnVectorOfAdaptBstr>* pe = 0;
6 HRESULT hr = pe->CreateInstance(&pe);
7 if( SUCCEEDED(hr) ) {
8 pe->AddRef();
9
10 hr = pe->Init(this->GetUnknown(), m_rgPrimes);
11 if (SUCCEEDED(hr)) {
12 hr = pe->QueryInterface(ppunkEnum);
13 }
14
15 pe->Release();
16 }
17
18 return hr;
19}
Using ICollectionOnSTLImpl with CAdapt
If you want to combine the use of ICollectionOnSTLImpl with CAdapt, you already
have half the tools: the custom copy policy and the enumeration
type definition. You still need another custom copy policy that
copies from the vector of CAdapt<CComBSTR> to the BSTR* that the client provides to implement get_Item. This copy policy can be implemented like
this:
1struct _CopyBstrFromAdaptBstr {
2 static HRESULT copy(BSTR* p1, CAdapt<CComBSTR>* p2) {
3 *p1 = SysAllocString(p2->m_T);
4 return (p1 ? S_OK : E_OUTOFMEMORY);
5 }
6
7 static void init(BSTR* p) { }
8 static void destroy(BSTR* p) { SysFreeString(*p); }
9};
Finally, we can use CAdapt with ICollectionOnSTLImpl like this:
1typedef IDispatchImpl<IPrimeNumberWords, &IID_IPrimeNumberWords>
2 IPrimeNumberWordsDualImpl;
3
4typedef ICollectionOnSTLImpl<IPrimeNumberWordsDualImpl,
5 vector< CAdapt<CComBSTR> >,
6 BSTR,
7 _CopyBstrFromAdaptBstr,
8 CComEnumVariantOnVectorOfAdaptBstr>
9 IPrimeNumberWordsCollImpl;
10
11class ATL_NO_VTABLE CPrimeNumberWords :
12 public CComObjectRootEx<CComSingleThreadModel>,
13 public CComCoClass<CPrimeNumberWords,
14 &CLSID_PrimeNumberWords>,
15 public IPrimeNumberWordsCollImpl {
16public:
17...
18// IPrimeNumberWords
19public:
20 STDMETHODIMP CalcPrimes(long min, long max) {
21 while (min <= max) {
22 if (IsPrime(min)) {
23 char sz[64];
24 CComBSTR bstr = NumWord(min, sz);
25 m_coll.push_back(bstr);
26 }
27 ++min;
28 }
29
30 return S_OK;
31 }
32};
ATL Collections
Using standard C++ puts one burden firmly on the shoulders of the developer: exception handing. Many calls into collections and algorithms can cause exceptions that must be caught before they leave the method boundary. [5] And because C++ exception handling requires the C runtime (CRT), the CRT libraries must be linked with any ATL project that uses the standard C++ library. Although ATL servers do link with the CRT by default, it remains the case that some ATL servers are built without the CRT; therefore, an alternative for the standard library is needed. ATL includes three classes that provide basic array, list, and map functionality that are not unlike the C++ vector, list, and map classes. In the spirit of ATL, none of these classes throws exceptions or requires the CRT. Arguably more compelling than freedom from the CRT, these classes are specialized to yield additional classes tailored for use with COM by automatically managing collections of types such as interfaces.
CAtlArray
This class is a dynamically sized array that grows on demand. It is a template class, so it can hold any kind of data. Its declaration is as follows:
1template< typename E, class ETraits = CElementTraits< E > >
2class CatlArray {
3
4public:
5 CAtlArray() ;
6 ~CAtlArray() ;
7
8 size_t GetCount() const ;
9 bool IsEmpty() const ;
10 bool SetCount( size_t nNewSize, int nGrowBy = -1 );
11
12 void FreeExtra() ;
13 void RemoveAll() ;
14
15 const E& GetAt( size_t iElement ) const;
16 E& GetAt( size_t iElement );
17
18 const E* GetData() const ;
19 E* GetData() ;
20
21 void SetAt( size_t iElement, INARGTYPE element );
22 void SetAtGrow( size_t iElement, INARGTYPE element );
23
24 size_t Add();
25 size_t Add( INARGTYPE element );
26 size_t Append( const CAtlArray< E, ETraits >& aSrc );
27
28 void Copy( const CAtlArray< E, ETraits >& aSrc );
29
30 const E& operator[]( size_t iElement ) const;
31 E& operator[]( size_t iElement );
32
33 void InsertAt( size_t iElement, INARGTYPE element,
34 size_t nCount = 1 );
35 void InsertArrayAt( size_t iStart,
36 const CAtlArray< E, ETraits >* paNew );
37 void RemoveAt( size_t iElement, size_t nCount = 1 );
38
39#ifdef _DEBUG
40 void AssertValid() const;
41#endif // _DEBUG
42
43// Implementation
44private:
45 E* m_pData;
46 size_t m_nSize;
47 size_t m_nMaxSize;
48 int m_nGrowBy;
49
50 // Private to prevent use
51 CAtlArray( const CAtlArray& ) ;
52 CAtlArray& operator=( const CAtlArray& ) ;
53};
The class members manage the memory associated
with the m_pData member, a dynamically sized array of type E. The second template parameter (Etraits) to the CAtlArray class is the key to understanding how ATL
supports collections of different element types. This class
provides methods for copying elements, comparing elements, moving
elements, and computing element hash values for building hash
tables. By default, CAtlArray uses a template class called CElementTraits that supplies implementations of these
element policies that are appropriate for simple data types.
Storing more complex objects typically requires “overriding” these default policies by passing in an alternate
class for the ETRaits parameter. Indeed, you’ll see in a
moment that ATL does precisely this to provide more specialized
collection classes for dealing with commonly used types such as
interfaces.
Here are the five static member functions and
two typedefs ATL expects you to provide for the class specified as
the Etraits template parameter. In these method
signatures, T represents the element type.
1typedef const T& INARGTYPE; // type to be used for
2 // adding elements
3typedef T& OUTARGTYPE; // type to be used for
4 // retrieving elements
5
6static bool CompareElements( const T& element1,
7 const T& element2 );
8
9static int CompareElementsOrdered( const T& element1,
10 const T& element2 );
11
12static ULONG Hash( const T& element ) ;
13
14static void CopyElements( T* pDest, const T* pSrc,
15 size_t nElements );
16
17static void RelocateElements( T* pDest, T* pSrc,
18 size_t nElements );
The default CElementTraits class that AtlArray uses ultimately resolves to CDefaultElementTraits when primitive types such as int and bool are specified as the array element
type. This class supplies the required static member functions
through three base classes, one providing the comparison policy,
one encapsulating the hashing algorithm, and another supplying the
correct element copy semantics.
1template< typename T >
2class CDefaultElementTraits :
3 public CElementTraitsBase< T >,
4 public CDefaultHashTraits< T >,
5 public CDefaultCompareTraits< T >
6{ ... };
ATL provides template specializations of the CElementTraits class that automatically handle the unique
comparison and copying semantics of the CComBSTR and CComVariant smart types. Additionally, a different hashing
algorithm is used forthese types to
produce a better statistical distribution of hash keys than would
result with the trivial algorithm used for primitive types.
For dealing with arrays of interfaces, ATL
provides CInterfaceArray. Its definition simply derives
from CAtlArray and uses CComQIPtr as the array
element type and a special interface-savvy element traits
class.
1template< class I, const IID* piid = &__uuidof( I ) >
2class CInterfaceArray :
3 public CAtlArray< ATL::CComQIPtr< I, piid >,
4 CComQIPtrElementTraits< I, piid > >
5{ ... }
A special array type called CAutoPtrArray is also available for dealing with arrays of
smart pointers. It is also defined in terms of CAtlArray.
1template< typename E >
2class CAutoPtrArray :
3 public CAtlArray< ATL::CAutoPtr< E >,
4 CAutoPtrElementTraits< E > >
5{ ... }
Here’s how you might use CInterfaceArray in code:
1void GetPrimes(CInterfaceArray<IPrimeCalc>* prgCalc) {
2 // Declare array of IPrimeCalc interface pointers
3 CInterfaceArray<IPrimeCalc> rgCalc;
4
5 // Populate array
6 for (int i = 0; i < 50; i++) {
7 IPrimeCalc* pCalc = NULL;
8 ::CoCreateInstance(CLSID_CPrimeCalc, NULL, CLSCTX_ALL,
9 __uuidof(pCalc), (void**)&pCalc);
10
11 rgCalc[i] = pCalc; // ERROR: operator[] doesn't grow array
12
13 rgCalc.Add(pCalc); // grows array, inserts, calls AddRef
14 pCalc->Release();
15 }
16
17 *prgCalc = rgCalc; // ERROR: operator= marked private
18 // to prevent use
19
20 prgCalc->InsertArrayAt(0, &rgCalc); // OK, prgCalc has
21 // 50 AddRef'd itfs
22} // CInterfaceArray destructor calls
23 // Release on all elements in rgCalc
Unfortunately, CAtlArray isn’t very useful
for implementing an enumeration interface, even though it could be
easily used with CComEnum, because you’re not likely to
want to hold data in the same type as is being enumerated. Because CComEnum doesn’t support conversion on demand as CComEnumOnSTL does, you must manually convert your CAtlArray data into an array of data appropriate for
enumerating.
CAtlList
The CAtlList collection class provides
a convenient way to store objects in an ordered list. Compared to CAtlArray, inserting elements into CAtlList is
quite fast because it occurs in constant time. However, you can’t
access the elements in a list by index as you can with an array.
Like its array-based cousin, CAtlList is defined in terms
of an element traits class that encapsulates the details of dealing
with individual items in the list.
1template< typename E, class ETraits = CElementTraits< E > >
2class CAtlList {
3public:
4 typedef typename ETraits::INARGTYPE INARGTYPE;
5
6private:
7 class CNode : ... {
8 ...
9 public:
10 CNode* m_pNext;
11 CNode* m_pPrev;
12 E m_element;
13 };
14
15public:
16 CAtlList( UINT nBlockSize = 10 ) ;
17 ~CAtlList() ;
18
19 size_t GetCount() const ;
20 bool IsEmpty() const ;
21
22 E& GetHead() ;
23 const E& GetHead() const ;
24 E& GetTail() ;
25 const E& GetTail() const ;
26 E RemoveHead();
27 E RemoveTail();
28 void RemoveHeadNoReturn() ;
29 void RemoveTailNoReturn() ;
30
31 POSITION AddHead();
32 POSITION AddHead( INARGTYPE element );
33 void AddHeadList( const CAtlList< E, ETraits >* plNew );
34
35 POSITION AddTail();
36 POSITION AddTail( INARGTYPE element );
37 void AddTailList( const CAtlList< E, ETraits >* plNew );
38
39 void RemoveAll() ;
40
41 POSITION GetHeadPosition() const ;
42 POSITION GetTailPosition() const ;
43 E& GetNext( POSITION& pos ) ;
44 const E& GetNext( POSITION& pos ) const ;
45 E& GetPrev( POSITION& pos ) ;
46 const E& GetPrev( POSITION& pos ) const ;
47
48 E& GetAt( POSITION pos ) ;
49 const E& GetAt( POSITION pos ) const ;
50 void SetAt( POSITION pos, INARGTYPE element );
51 void RemoveAt( POSITION pos ) ;
52
53 POSITION InsertBefore( POSITION pos, INARGTYPE element );
54 POSITION InsertAfter( POSITION pos, INARGTYPE element );
55
56 POSITION Find( INARGTYPE element,
57 POSITION posStartAfter = NULL ) const ;
58 POSITION FindIndex( size_t iElement ) const ;
59
60 void MoveToHead( POSITION pos ) ;
61 void MoveToTail( POSITION pos ) ;
62 void SwapElements( POSITION pos1, POSITION pos2 ) ;
63
64// Implementation
65private:
66 CNode* m_pHead;
67 CNode* m_pTail;
68 CNode* m_pFree;
69 ...
70};
This class manages a doubly linked list of CNode objects, each of which simply hold pointers to the
data of the specified type (E), as well as pointers to the
previous and next nodes in the list. Two list classes are also
provided for dealing with smart pointers and interface pointers: CAutoPtrList and CInterfaceList. As with their
array-based counterparts, these classes simply use CAtlList as their base class and specify type-specific
element trait classes.
1template< class I, const IID* piid = &__uuidof( I ) >
2class CInterfaceList :
3 public CAtlList< ATL::CComQIPtr< I, piid >,
4 CComQIPtrElementTraits< I, piid > >
5{ ... }
6
7template< typename E >
8class CAutoPtrList :
9 public CAtlList< ATL::CAutoPtr< E >,
10 CAutoPtrElementTraits< E > >
11{ ... }
CAtlMap
If you want the functionality of the C++ map
class, ATL provides CAtlMap:
1template< typename K, typename V,
2 class KTraits = CElementTraits< K >,
3 class VTraits = CElementTraits< V > >
4class CAtlMap {
5public:
6 typedef typename KTraits::INARGTYPE KINARGTYPE;
7 typedef typename KTraits::OUTARGTYPE KOUTARGTYPE;
8 typedef typename VTraits::INARGTYPE VINARGTYPE;
9 typedef typename VTraits::OUTARGTYPE VOUTARGTYPE;
10
11 class CPair : ... {
12 public:
13 const K m_key;
14 V m_value;
15 };
16
17private:
18 class CNode : public CPair { ... }
19
20public:
21 ...
22 size_t GetCount() const ;
23 bool IsEmpty() const ;
24
25 bool Lookup( KINARGTYPE key, VOUTARGTYPE value ) const;
26 const CPair* Lookup( KINARGTYPE key ) const ;
27 CPair* Lookup( KINARGTYPE key ) ;
28 V& operator[]( KINARGTYPE key ) ;
29
30 POSITION SetAt( KINARGTYPE key, VINARGTYPE value );
31 void SetValueAt( POSITION pos, VINARGTYPE value );
32
33 bool RemoveKey( KINARGTYPE key ) ;
34 void RemoveAll() ;
35 void RemoveAtPos( POSITION pos ) ;
36
37 POSITION GetStartPosition() const ;
38 void GetNextAssoc( POSITION& pos, KOUTARGTYPE key,
39 VOUTARGTYPE value ) const;
40 const CPair* GetNext( POSITION& pos ) const ;
41 CPair* GetNext( POSITION& pos ) ;
42 const K& GetNextKey( POSITION& pos ) const ;
43 const V& GetNextValue( POSITION& pos ) const ;
44 V& GetNextValue( POSITION& pos ) ;
45 void GetAt( POSITION pos, KOUTARGTYPE key,
46 VOUTARGTYPE value ) const;
47 CPair* GetAt( POSITION pos ) ;
48 const CPair* GetAt( POSITION pos ) const ;
49 const K& GetKeyAt( POSITION pos ) const ;
50 const V& GetValueAt( POSITION pos ) const ;
51 V& GetValueAt( POSITION pos ) ;
52
53 UINT GetHashTableSize() const ;
54 bool InitHashTable( UINT nBins, bool bAllocNow = true );
55 void EnableAutoRehash() ;
56 void DisableAutoRehash() ;
57 void Rehash( UINT nBins = 0 );
58 void SetOptimalLoad( float fOptimalLoad, float fLoThreshold,
59 float fHiThreshold, bool bRehashNow = false );
60
61// Implementation
62private:
63 CNode** m_ppBins;
64 CNode* m_pFree;
65 ...
66};
CAtlMap maintains a list of nodes, each of which holds a key and a value.
In this case, element trait classes must be provided for both the
key type and the value type. The key is used to generate a hash for
locating nodes in the list. CAtlMap would be useful for
implementing collection item lookup by name instead of by
index.
Be aware that CAtlMap does not have the
same performance guarantees as the C++ std::map<> container. std::map<> uses a balanced binary tree
that guarantees O(lg N) performance for inserts or lookups. CAtlMap, on the other hand, uses a hash table. Under good
conditions, the hash table can give O(1) lookup performance, but a
bad hash function can reduce the hash table to linear searches.
Object Models
A COM object model is a hierarchy of objects. Collections allow the subobjects to be manipulated. Enumerators allow these objects to be accessed. Most object models have one top-level object and several noncreateable subobjects. The following stylized IDL shows a minimal object model:
1library OBJECTMODELLib {
2 importlib("stdole32.tlb");
3 importlib("stdole2.tlb");
4
5 // Document sub-object ////////////////////////////////////
6 [ object, dual ] interface IDocument : IDispatch {
7 [propget] HRESULT Data([out, retval] BSTR *pVal);
8 [propput] HRESULT Data([in] BSTR newVal);
9 };
10
11 coclass Document {
12 [default] interface IDocument;
13 };
14
15 // Documents collection ///////////////////////////////////
16 [ object, dual ] interface IDocuments : IDispatch {
17 HRESULT AddDocument([out, retval] IDocument** ppDocument);
18 [propget] HRESULT Count([out, retval] long* pnCount);
19 [id(DISPID_VALUE), propget]
20 HRESULT Item([in] long n, [out, retval] IDocument** ppdoc);
21 [id(DISPID_NEWENUM), propget]
22 HRESULT _NewEnum([out, retval] IUnknown** ppEnum);
23 };
24
25 coclass Documents {
26 [default] interface IDocuments;
27 };
28
29 // Application top-level object ///////////////////////////
30 [ object, dual ] interface IApplication : IDispatch {
31 [propget] HRESULT Documents(
32 [out, retval] IDocuments** pVal);
33 };
34
35 coclass Application {
36 [default] interface IApplication;
37 };
38};
An instance hierarchy of this object model looks like Figure 8.3.
Figure 8.3. Simple object model instance hierarchy
Implementing the Top-Level Object
The top-level object of an object model is createable and exposes any number of properties and any number of collection subobjects. The example implementation looks like the following:
1class ATL_NO_VTABLE CApplication :
2 public CComObjectRootEx<CComSingleThreadModel>,
3 public CComCoClass<CApplication, &CLSID_Application>,
4 public IDispatchImpl<IApplication, &IID_IApplication> {
5public:
6DECLARE_REGISTRY_RESOURCEID(IDR_APPLICATION)
7DECLARE_NOT_AGGREGATABLE(CApplication)
8DECLARE_PROTECT_FINAL_CONSTRUCT()
9
10BEGIN_COM_MAP(CApplication)
11 COM_INTERFACE_ENTRY(IApplication)
12 COM_INTERFACE_ENTRY(IDispatch)
13END_COM_MAP()
14
15 // Create instance of the Documents collection
16 HRESULT CApplication::FinalConstruct()
17 { return CDocuments::CreateInstance(&m_spDocuments); }
18
19// IApplication
20public:
21 // Hand out the Documents collection to interested parties
22 STDMETHODIMP CApplication::get_Documents(IDocuments** pVal)
23 { return m_spDocuments.CopyTo(pVal); }
24
25private:
26 CComPtr<IDocuments> m_spDocuments;
27};
Implementing the Collection Object
The collection object is the most difficult of the three layers to implement, not because of any difficult code, but because of the maze of type definitions. The first set is required to implement the enumerator:
1template <typename T>
2struct _CopyVariantFromAdaptItf {
3 static HRESULT copy(VARIANT* p1, CAdapt< CComPtr<T> >* p2) {
4 HRESULT hr = p2->m_T->QueryInterface(IID_IDispatch,
5 (void**)&p1->pdispVal);
6 if (SUCCEEDED(hr)) {
7 p1->vt = VT_DISPATCH;
8 }
9 else {
10 hr = p2->m_T->QueryInterface(IID_IUnknown,
11 (void**)&p1->punkVal);
12 if( SUCCEEDED(hr) ) {
13 p1->vt = VT_UNKNOWN;
14 }
15 }
16
17 return hr;
18 }
19
20 static void init(VARIANT* p) { VariantInit(p); }
21 static void destroy(VARIANT* p) { VariantClear(p); }
22};
23typedef CComEnumOnSTL<IEnumVARIANT, &IID_IEnumVARIANT, VARIANT,
24 _CopyVariantFromAdaptItf<IDocument>,
25 list< CAdapt< CComPtr<IDocument> > > >
26 CComEnumVariantOnListOfDocuments;
The _CopyVariantFromAdaptItf class is a
reusable class that converts an interface into a VARIANT for use in enumerating a collection of interface pointers. The
collection object is expected to hold a C++ container of elements
of type CAdapt<CComPtr<T>>. Notice how the
copy policy is used in the type definition of CComEnumVariantsOnListOfDocuments to obtain the
implementation of IEnumVARIANT for the collection
object.
The next set of type definitions is for the implementation of the collection methods:
1template <typename T>
2struct _CopyItfFromAdaptItf {
3 static HRESULT copy(T** p1, CAdapt< CComPtr<T> >* p2) {
4 if( *p1 = p2->m_T ) return (*p1)->AddRef(), S_OK;
5 return E_POINTER;
6 }
7
8 static void init(T** p) {}
9 static void destroy(T** p) { if( *p ) (*p)->Release(); }
10};
11
12typedef ICollectionOnSTLImpl<
13 IDispatchImpl<IDocuments, &IID_IDocuments>,
14 list< CAdapt< CComPtr<IDocument> > >,
15 IDocument*,
16 _CopyItfFromAdaptItf<IDocument>,
17 CComEnumVariantOnListOfDocuments>
18 IDocumentsCollImpl;
The _CopyItfFromAdaptItf is used to
implement the Item property, again assuming a C++
container holding elements of type CAdapt<CComPtr<T>>. The copy policy is then
used to define the collection interface implementation, IDocumentsCollImpl.
Finally, IDocumentsCollImpl is used as
the base class of the IDocuments implementation:
1class ATL_NO_VTABLE CDocuments :
2 public CComObjectRootEx<CComSingleThreadModel>,
3 public CComCoClass<CDocuments>, // noncreateable
4 public IDocumentsCollImpl
5{
6public:
7DECLARE_NO_REGISTRY()
8DECLARE_NOT_AGGREGATABLE(CDocuments)
9DECLARE_PROTECT_FINAL_CONSTRUCT()
10
11BEGIN_COM_MAP(CDocuments)
12 COM_INTERFACE_ENTRY(IDocuments)
13 COM_INTERFACE_ENTRY(IDispatch)
14END_COM_MAP()
15
16// IDocuments
17public:
18 STDMETHODIMP AddDocument(IDocument** ppDocument) {
19 // Create a document to hand back to the client
20 HRESULT hr = CDocument::CreateInstance(ppDocument);
21 if( SUCCEEDED(hr) ) {
22 // Put the document on the list
23 CComPtr<IDocument> spDoc = *ppDocument;
24 m_coll.push_back(spDoc);
25 }
26
27 return hr;
28 }
29};
The benefit of all the type
definitions is that the standard methods of the collection are
implemented for us. We only have to implement the AddDocument method, which creates a new CDocument and adds it to the list that the ICollectionOnSTLImpl base
class maintains.
Implementing the Subobjects
The subobjects can do whatever you want,
including maintaining collections of objects further down the
hierarchy. Our example maintains a BSTR, representing its
data:
1STDMETHODIMP CDocument::get_Data(BSTR *pVal) {
2 return m_bstrData.CopyTo(pVal);
3}
4STDMETHODIMP CDocument::put_Data(BSTR newVal) {
5 m_bstrData = newVal;
6 return (m_bstrData || !newVal ? S_OK : E_OUTOFMEMORY);
7}
Using the Object Model
You normally design an object model to be used by many language mappings, including scripting environments. Here’s an example HTML page that uses this example object model:
1<html>
2<script language=vbscript>
3 dim app
4 set app = CreateObject("ObjectModel.Application")
5
6 dim docs
7 set docs = app.Documents
8
9 dim doc
10 set doc = docs.AddDocument
11 doc.Data = "Document 1"
12
13 set doc = docs.AddDocument
14 doc.Data = "Document 2"
15
16 for each doc in docs
17 msgbox doc.data
18 next
19</script>
20</html>
Summary
COM has abstractions much like those of the C++ standard library. Collections maintain lists of things, often objects. Enumerators enable navigation over the list of things maintained in a collection. To standardize access to collections and enumerators, they have a standard protocol. These standards aren’t required, but if they are followed, they make an object model programmer’s life easier because the usage is familiar. Implementing an object model is a matter of defining the higher-level object, the lower-level object, and the collection that joins the two. ATL implements both collection and enumeration interfaces, if you’re not afraid of the type definitions required to make it all work.