Chapter 14. ATL Server Internals
ATL Server provides a robust implementation of an ISAPI extension right out of the box. It manages threading and IIS resources so you don’t have to. You’ve already seen how to use ATL Server in Chapter 13, “Hello, ATL Server”; now let’s take a look under the hood and see how it works.
Implementing ISAPI in ATL Server
The CIsapiExtension class is the heart
of ATL’s implementation of the ISAPI interface.
1template <class ThreadPoolClass=CThreadPool<CIsapiWorker>,
2 class CRequestStatClass=CNoRequestStats,
3 class HttpUserErrorTextProvider=CDefaultErrorProvider,
4 class WorkerThreadTraits=DefaultThreadTraits,
5 class CPageCacheStats=CNoStatClass,
6 class CStencilCacheStats=CNoStatClass>
7class CIsapiExtension :
8 public IServiceProvider,
9 public IIsapiExtension,
10 public IRequestStats {
11protected:
12 CIsapiExtension();
13
14 DWORD HttpExtensionProc(LPEXTENSION_CONTROL_BLOCK lpECB) ;
15 BOOL GetExtensionVersion(__out HSE_VERSION_INFO* pVer) ;
16 BOOL TerminateExtension(DWORD /*dwFlags*/) ;
17
18 // ...
19};
As you can see, this class is heavily templated.
Three of the template parameters (CRequestStatClass,
CPageCacheStats, and CStencilCacheStats) are used
for performance tracking and logging. The default template
parameters result in no logging or performance counters being used; ATL
Server provides other implementation that will gather statistics
for you, but because that logging can have a significant
performance impact, it’s turned off by default.
The three CIsapiExtension methods
contain the actual implementations of the three ISAPI functions.
The GetExtensionVersion method is long but fairly
straightforward. Because this is the method called when the ISAPI
extension is first loaded, the class does most of its
initialization here:
1BOOL GetExtensionVersion( HSE_VERSION_INFO* pVer) {
2 // allocate a Tls slot for storing per thread data
3 m_dwTlsIndex = TlsAlloc();
4
5 // create a private heap for request data
6 // this heap has to be thread safe to allow for
7 // async processing of requests
8 m_hRequestHeap = HeapCreate(0, 0, 0);
9 if (!m_hRequestHeap) {
10 m_hRequestHeap = GetProcessHeap();
11 if (!m_hRequestHeap) {
12 return SetCriticalIsapiError(IDS_ATLSRV_CRITICAL_HEAPCREATEFAILED);
13 }
14 }
15
16 // create a private heap (synchronized) for
17 // allocations. This reduces fragmentation overhead
18 // as opposed to the process heap
19 HANDLE hHeap = HeapCreate(0, 0, 0);
20 if (!hHeap) {
21 hHeap = GetProcessHeap();
22 m_heap.Attach(hHeap, false);
23 } else {
24 m_heap.Attach(hHeap, true);
25 }
26 hHeap = NULL;
27
28 if (S_OK != m_WorkerThread.Initialize()) {
29 return SetCriticalIsapiError(IDS_ATLSRV_CRITICAL_WORKERINITFAILED);
30 }
31
32 if (m_critSec.Init() != S_OK) {
33 HRESULT hrIgnore=m_WorkerThread.Shutdown();
34 return SetCriticalIsapiError(IDS_ATLSRV_CRITICAL_CRITSECINITFAILED);
35 }
36 if (S_OK != m_ThreadPool.Initialize(
37 static_cast<IIsapiExtension*>(this), GetNumPoolThreads(),
38 GetPoolStackSize(), GetIOCompletionHandle())) {
39 HRESULT hrIgnore=m_WorkerThread.Shutdown();
40 m_critSec.Term();
41 return SetCriticalIsapiError(
42 IDS_ATLSRV_CRITICAL_THREADPOOLFAILED);
43 }
44
45 if (FAILED(m_DllCache.Initialize(&m_WorkerThread,
46 GetDllCacheTimeout()))) {
47 HRESULT hrIgnore=m_WorkerThread.Shutdown();
48 m_ThreadPool.Shutdown();
49 m_critSec.Term();
50 return SetCriticalIsapiError(
51 IDS_ATLSRV_CRITICAL_DLLCACHEFAILED);
52 }
53
54 if (FAILED(m_PageCache.Initialize(&m_WorkerThread))) {
55 HRESULT hrIgnore=m_WorkerThread.Shutdown();
56 m_ThreadPool.Shutdown();
57 m_DllCache.Uninitialize();
58 m_critSec.Term();
59 return SetCriticalIsapiError(
60 IDS_ATLSRV_CRITICAL_PAGECACHEFAILED);
61 }
62
63 if (S_OK != m_StencilCache.Initialize(
64 static_cast<IServiceProvider*>(this),
65 &m_WorkerThread,
66 GetStencilCacheTimeout(),
67 GetStencilLifespan())) {
68 HRESULT hrIgnore=m_WorkerThread.Shutdown();
69 m_ThreadPool.Shutdown();
70 m_DllCache.Uninitialize();
71 m_PageCache.Uninitialize();
72 m_critSec.Term();
73 return SetCriticalIsapiError(IDS_ATLSRV_CRITICAL_STENCILCACHEFAILED);
74 }
75
76 pVer->dwExtensionVersion = HSE_VERSION;
77 Checked::strncpy_s(pVer->lpszExtensionDesc,
78 HSE_MAX_EXT_DLL_NAME_LEN, GetExtensionDesc(), _TRUNCATE);
79 pVer->lpszExtensionDesc[HSE_MAX_EXT_DLL_NAME_LEN - 1] = '\0';
80
81 return TRUE;
82}
This method allocates two Win32 heaps for use during request process, sets up a thread pool, and initializes various caches.
The real action takes place in the
HttpExtensionProc method. This is called for every HTTP
request that IIS routes to our extension DLL. Before we look at the
implementation of this method, we need to look at how to achieve
high performance in a server environment.
Performance and Multithreading
Any production web server needs to handle many simultaneous network requests. In the original web extension platform, the Common Gateway Interface (CGI), each request was handled by spawning a new process. This process handled that one request and then exited. This worked acceptably on UNIX for small sites, but process creation overhead soon limited the number of simultaneous requests that could be processed.
This process-creation model was made even worse on Windows, where creating processes is much more expensive. However, there’s a fairly obvious alternative in Win32: use a thread per request instead of a process. Threads are much, much cheaper to start. Unfortunately, the obvious solution is somewhat less obviously wrong in large systems. Threads might be cheap, but they’re not free. As the number of threads increases, the CPU spends more time on thread management and less time actually doing the work of serving your web site.
The solution comes from the stateless nature of HTTP. Because each request is independent, it doesn’t matter which specific thread processes a request. More usefully, when a thread is done processing a request, instead of dying, it can be reused to process another request. This design is called a thread pool.
IIS uses a thread pool internally to handle
incoming traffic. Each request is handed off to a thread in the
pool. The thread services the request (by either returning static
content off the disk or executing the HttpExtensionProc of
the appropriate ISAPI extension DLL). In general, this works well,
but the thread has to finish its processing quickly. If all the
threads in the IIS pool are busy, new requests start getting
dropped. Serving static content is a low-overhead process. But when
you start executing arbitrary code (to generate dynamic HTML, for
example), suddenly the time it takes for the thread to return to
the pool is much less predictable, and it could be much longer.
So, we need to return the IIS thread back to the
pool as soon as possible. But we also need to actually perform our
processing to handle the request. Instead of forcing every
developer to micro-optimize every statement of the ISAPI extension
to get the thread back to the pool, ATL
Server provides its own thread pool. On a request, the
HttpExtensionProc (which is running on the IIS thread)
places the request into the internal thread pool. The IIS thread
then returns, ready to process another request. The code
follows:
1DWORD HttpExtensionProc(LPEXTENSION_CONTROL_BLOCK lpECB) {
2 AtlServerRequest *pRequestInfo = NULL;
3 _ATLTRY {
4 pRequestInfo = CreateRequest();
5 if (pRequestInfo == NULL)
6 return HSE_STATUS_ERROR;
7
8 CServerContext *pServerContext = NULL;
9 ATLTRY(pServerContext = CreateServerContext(m_hRequestHeap));
10 if (pServerContext == NULL) {
11 FreeRequest(pRequestInfo);
12 return HSE_STATUS_ERROR;
13 }
14
15 pServerContext->Initialize(lpECB);
16 pServerContext->AddRef();
17
18 pRequestInfo->pServerContext = pServerContext;
19 pRequestInfo->dwRequestType = ATLSRV_REQUEST_UNKNOWN;
20 pRequestInfo->dwRequestState = ATLSRV_STATE_BEGIN;
21 pRequestInfo->pExtension =
22 static_cast<IIsapiExtension *>(this);
23 pRequestInfo->pDllCache =
24 static_cast<IDllCache *>(&m_DllCache);
25#ifndef ATL_NO_MMSYS
26 pRequestInfo->dwStartTicks = timeGetTime();
27#else
28 pRequestInfo->dwStartTicks = GetTickCount();
29#endif
30 pRequestInfo->pECB = lpECB;
31
32 m_reqStats.OnRequestReceived();
33
34 if (m_ThreadPool.QueueRequest(pRequestInfo))
35 return HSE_STATUS_PENDING;
36
37 if (pRequestInfo != NULL) {
38 FreeRequest(pRequestInfo);
39 }
40 }
41 _ATLCATCHALL() { }
42 return HSE_STATUS_ERROR;
43}
The
CreateRequest method simply allocates a chunk of memory
from the request heap to store the information about the
request:
1struct AtlServerRequest {
2 // For future compatibility
3 DWORD cbSize;
4
5 // Necessary because it wraps the ECB
6 IHttpServerContext *pServerContext;
7
8 // Indicates whether it was called through an .srf file or
9 // through a .dll file
10 ATLSRV_REQUESTTYPE dwRequestType;
11 // Indicates what state of completion the request is in
12 ATLSRV_STATE dwRequestState;
13 // Necessary because the callback (for async calls) must
14 // know where to route the request
15 IRequestHandler *pHandler;
16 // Necessary in order to release the dll properly
17 // (for async calls)
18 HINSTANCE hInstDll;
19 // Necessary to requeue the request (for async calls)
20 IIsapiExtension *pExtension;
21 // Necessary to release the dll in async callback
22 IDllCache* pDllCache;
23
24 HANDLE hFile;
25 HCACHEITEM hEntry;
26 IFileCache* pFileCache;
27
28 // necessary to synchronize calls to HandleRequest
29 // if HandleRequest could potentially make an
30 // async call before returning. only used
31 // if indicated with ATLSRV_INIT_USEASYNC_EX
32 HANDLE m_hMutex;
33 // Tick count when the request was received
34 DWORD dwStartTicks;
35 EXTENSION_CONTROL_BLOCK *pECB;
36 PFnHandleRequest pfnHandleRequest;
37 PFnAsyncComplete pfnAsyncComplete;
38 // buffer to be flushed asynchronously
39 LPCSTR pszBuffer;
40 // length of data in pszBuffer
41 DWORD dwBufferLen;
42 // value that can be used to pass user data between
43 // parent and child handlers
44 void* pUserData;
45};
46
47AtlServerRequest *CreateRequest() {
48 // Allocate a fixed block size to avoid fragmentation
49 AtlServerRequest *pRequest = (AtlServerRequest *) HeapAlloc(
50 m_hRequestHeap, HEAP_ZERO_MEMORY,
51 __max(sizeof(AtlServerRequest),
52 sizeof(_CComObjectHeapNoLock<CServerContext>)));
53 if (!pRequest) return NULL;
54
55 pRequest->cbSize = sizeof(AtlServerRequest);
56 return pRequest;
57}
As you can see, there’s all the information that IIS supplies about the request (the ECB pointer), plus a whole lot more.
The ATL Server Thread Pool
ATL Server provides a thread pool implementation
in the CThreadPool class:
1template <class Worker,
2 class ThreadTraits=DefaultThreadTraits,
3 class WaitTraits=DefaultWaitTraits>
4class CThreadPool : public IThreadPoolConfig {
5 // ...
6};
The template parameters give you control over
how threads are created and what they do. The Worker
template parameter lets you specify what class will actually do the
processing of the request. The ThreadTraits class controls
how a thread is created. Depending on the ATL_MIN_CRT
setting, DefaultThreadTraits is a typedef to one of two
other classes:
1class CRTThreadTraits {
2public:
3 static HANDLE CreateThread(LPSECURITY_ATTRIBUTES lpsa,
4 DWORD dwStackSize, LPTHREAD_START_ROUTINE pfnThreadProc,
5 void *pvParam, DWORD dwCreationFlags, DWORD *pdwThreadId) {
6 // _beginthreadex calls CreateThread
7 // which will set the last error value
8 // before it returns.
9 return (HANDLE) _beginthreadex(lpsa, dwStackSize,
10 (unsigned int (__stdcall *)(void *)) pfnThreadProc,
11 pvParam, dwCreationFlags, (unsigned int *) pdwThreadId);
12 }
13};
14
15class Win32ThreadTraits {
16public:
17 static HANDLE CreateThread(LPSECURITY_ATTRIBUTES lpsa,
18 DWORD dwStackSize, LPTHREAD_START_ROUTINE pfnThreadProc,
19 void *pvParam, DWORD dwCreationFlags, DWORD *pdwThreadId) {
20 return ::CreateThread(lpsa, dwStackSize, pfnThreadProc,
21 pvParam, dwCreationFlags, pdwThreadId);
22 }
23};
24
25#if !defined(_ATL_MIN_CRT) && defined(_MT)
26 typedef CRTThreadTraits DefaultThreadTraits;
27#else
28 typedef Win32ThreadTraits DefaultThreadTraits;
29#endif
As part of initialization, the CThreadPool
class uses the ThreadTraits class to create the initial
set of threads. The threads in the pool all run this thread
proc:
1DWORD ThreadProc() {
2 DWORD dwBytesTransfered;
3 ULONG_PTR dwCompletionKey;
4
5 OVERLAPPED* pOverlapped;
6
7 // this block is to ensure theWorker gets destructed before the
8 // thread handle is closed {
9 // We instantiate an instance of the worker class on the
10 // stack for the life time of the thread.
11 Worker theWorker;
12 if (theWorker.Initialize(m_pvWorkerParam) == FALSE) {
13 return 1;
14 }
15
16 SetEvent(m_hThreadEvent);
17 // Get the request from the IO completion port
18 while (GetQueuedCompletionStatus(m_hRequestQueue,
19 &dwBytesTransfered, &dwCompletionKey, &pOverlapped,
20 INFINITE)) {
21 if (pOverlapped == ATLS_POOL_SHUTDOWN) // Shut down {
22 LONG bResult = InterlockedExchange(&m_bShutdown, FALSE);
23 if (bResult) // Shutdown has not been cancelled
24 break;
25
26 // else, shutdown has been cancelled continue as before
27 }
28 else {
29 // Do work
30 Worker::RequestType request =
31 (Worker::RequestType) dwCompletionKey;
32
33 // Process the request. Notice the following:
34 // (1) It is the worker's responsibility to free any
35 // memory associated with the request if the request is
36 // complete
37 // (2) If the request still requires some more processing
38 // the worker should queue the request again for
39 // dispatching
40 theWorker.Execute(request, m_pvWorkerParam, pOverlapped);
41 }
42 }
43
44 theWorker.Terminate(m_pvWorkerParam);
45 }
46
47 m_dwThreadEventId = GetCurrentThreadId();
48 SetEvent(m_hThreadEvent);
49
50 return 0;
51}
The overall logic is fairly common in a thread pool. The thread sits waiting on the I/O Completion port for requests to come in. A special value is used to tell the thread to shut down; if it’s not shut down, the request is passed off to the worker object to do the actual work.
The worker class can be anything with a
RequestType typedef and the appropriate Execute
method.
At this point, ATL Server has already provided a
greatly improved ISAPI development experience. The hard work to
maintain the performance of the server has been done; all you need
to do is write a worker class and implement your logic in the
Execute method. This still leaves you with the job of
generating the HTML to send to the client. This isn’t too hard in
C++, [1] but it is tedious, and building HTML in
code means that you have to recompile to change a spelling error.
What’s really needed is some way to generate the HTML based on a
template. ATL Server does this via Server Response Files.
Server Response Files
ATL Server provides a text-replacement system
called Server Response Files (referred to in the ATL Server code
and documentation occasionally as Stencil Files). An .srf
file is an HTML file with some replacement markers. Consider this
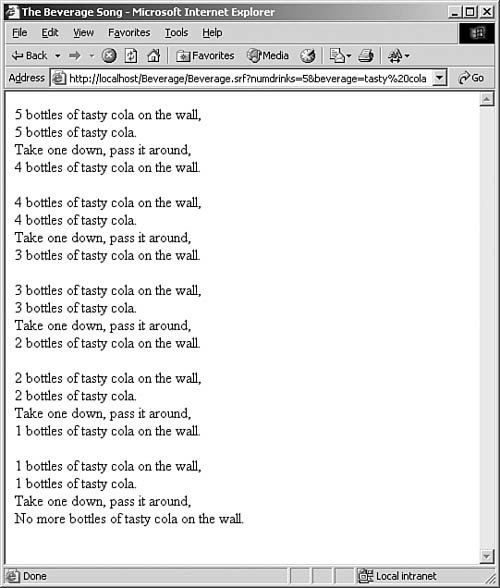
example, which is used to display the lyrics to a classic song:
1<html>
2{{handler Beverage.dll/Default}}
3<head>
4 <title>The Beverage Song</title>
5</head>
6<body>
7{{if InputValid}}
8{{while MoreDrinks}}
9<p/>
10{{DrinkNumber}} bottles of {{Beverage}} on the wall, <br />
11{{DrinkNumber}} bottles of {{Beverage}}.<br />
12Take one down, pass it around,<br />
13{{NextDrink}} bottles of {{Beverage}} on the wall.<br />
14{{endwhile}}
15{{else}}
16<h1>You must specify a beverage and the number of them
17 in the query string.</h1>
18{{endif}}
19</body>
20</html>
21<head>
As we discussed in
Chapter 13, the items
within {{ }} are used for one of three purposes. They can
be directives to the stencil processor (the handler
directive), they can work as flow control (if and
while), or they can be replaced at runtime by the request
handler class. Any text outside the markers is simply passed
straight to the output.
The actual replacements are handled by a class referred to a request handler. An example request handler for the song follows:
1class CBeverageHandler
2 : public CRequestHandlerT<CBeverageHandler> {
3
4public:
5 BEGIN_REPLACEMENT_METHOD_MAP(CBeverageHandler)
6 REPLACEMENT_METHOD_ENTRY("InputValid", OnInputValid)
7 REPLACEMENT_METHOD_ENTRY("MoreDrinks", OnMoreDrinks)
8 REPLACEMENT_METHOD_ENTRY("DrinkNumber", OnDrinkNumber)
9 REPLACEMENT_METHOD_ENTRY("Beverage", OnBeverage)
10 REPLACEMENT_METHOD_ENTRY("NextDrink", OnNextDrink)
11 END_REPLACEMENT_METHOD_MAP()
12
13 HTTP_CODE ValidateAndExchange() {
14 m_numDrinks = 0;
15 m_HttpRequest.GetQueryParams().Exchange( "numdrinks",
16 &m_numDrinks );
17 m_beverage =
18 m_HttpRequest.GetQueryParams().Lookup("beverage");
19
20 m_HttpResponse.SetContentType("text/html");
21
22 return HTTP_SUCCESS;
23 }
24
25protected:
26 HTTP_CODE OnInputValid( ) {
27 if( m_numDrinks == 0 || m_beverage.IsEmpty() ) {
28 return HTTP_S_FALSE;
29 }
30 return HTTP_SUCCESS;
31 }
32
33 HTTP_CODE OnMoreDrinks( ) {
34 if( m_numDrinks > 0 ) {
35 return HTTP_SUCCESS;
36 }
37 return HTTP_S_FALSE;
38 }
39
40 HTTP_CODE OnDrinkNumber( ) {
41 m_HttpResponse << m_numDrinks;
42 return HTTP_SUCCESS;
43 }
44
45 HTTP_CODE OnBeverage( ) {
46 m_HttpResponse << m_beverage;
47 return HTTP_SUCCESS;
48 }
49
50 HTTP_CODE OnNextDrink( ) {
51 m_numDrinks;
52 if( m_numDrinks > 0 ) {
53 m_HttpResponse << m_numDrinks;
54 } else {
55 m_HttpResponse << "No more";
56 }
57 return HTTP_SUCCESS;
58 }
59
60private:
61 long m_numDrinks;
62 CStringA m_beverage;
63};
Request handlers inherit
from the CRequestHandlerT base class. A request handler
needs to implement the ValidateAndExchange method, which
gets called at the start of processing the HTTP request. In
processing a form post, this is where you would process the
submitted form fields. If this function returns HTTP_FAIL,
the request is aborted and IIS sends back an HTTP 500 error to the
client.
If, as you would usually prefer,
ValidateAndExchange returns HTTP_SUCCESS, the
stencil processor starts rendering the SRF file. Each time a
replacement occurs, the processor calls back into the
response-handler object.
The REPLACEMENT_METHOD_MAP() macros in
the response-handler class are used to specify which methods should
be called for which replacement. In the previous code, this line
says that when the {{Beverage}} replacement is found in
the .srf file, the OnBeverage method should be
called:
1REPLACEMENT_METHOD_ENTRY("Beverage", OnBeverage)
Actually generating the
output is fairly simple using the m_HttpResponse member,
which is inherited from the CRequestHandlerT base class.
This is an instance of the CHttpResponse class, already
initialized and ready to use. Figure 14.1 shows the result of this page
running.
Figure 14.1. Some tasty beverages to sing about
![[View full size image]](_static/images/14atl01_alt.jpg){kind=link}
Request-Handler Routing
How does the stencil processor know which
response handler class to use? In the .srf file itself,
you might have noticed this line:
1{{handler Beverage.dll/Default}}
The handler directive says which DLL
the handler is in (Beverage.dll, in this case) and what
the name of the handler is (Default). This might seem
strange because the name of our handler class isn’t
Default; it’s CBeverageHandler. ATL Server isn’t
reading anybody’s mind here. Instead, a global map in the response
DLL provides the mapping between the name you use in
the handler directive and the actual class. If you look in
your request handler project’s .cpp file, you’ll see
something like this at global scope:
1// Beverage.cpp
2...
3BEGIN_HANDLER_MAP()
4 HANDLER_ENTRY("Default", CBeverageHandler)
5END_HANDLER_MAP()
This is one way to get your handler into the
map: Simply add a new HANDLER_ENTRY macro to the map every
time you add a new request-handler class. However, this global map
is difficult to maintain over time. It sure would be nice to have
the handler name with the class that handles it.
Much like the COM_OBJECT_ENTRY_AUTO
macro for ATL COM classes, there’s a macro that you can put in your
.h file instead: DECLARE_REQUEST_HANDLER. You use
it like this:
1class CBeverageHandler : ... { ... };
2
3DECLARE_REQUEST_HANDLER( "Default", CBeverageHandler,
4 ::CBeverageHandler )
This macro uses similar linker tricks to the
COM_OBJECT_ENTRY_AUTO macro to stitch together the tables
at link time. The default project generated by the ATL Server
project template uses HANDLER_ENTRY; for your own
request-handler classes, I would recommend using
DECLARE_REQUEST_HANDLER instead. Unfortunately,
DECLARE_REQUEST_HANDLER is undocumented at this time. The
parameters to the macro are, in order, the handler name, the name
of the request-handler class without any namespaces, and the name
of the request handler including the namespaces.
Now that you’ve seen the various pieces, let’s
look at the .srf-processing pipeline. The first stop for
the HTTP request is IIS. IIS checks its configuration and finds
that, for this virtual directory, it should route the request to
our ATL Server ISAPI Extension DLL.
So IIS loads (on the first request) the
extension DLL and calls the HttpExtensionProc method. This
immediately calls into the global instance of
CIsapiExtension.
CIsapiExtension takes the request,
builds a CServerContext object, places the request onto
its internal thread pool, and releases the IIS thread back to
handle another incoming request.
Meanwhile, the extension DLL’s thread-pool
threads are hungrily waiting for work to come in. The first one
available pulls the request off the internal queue and hands it to
the working class (which is, by default,
CIsapiWorker).
The actual work is done in
the Execute() method:
1void CIsapiWorker::Execute(AtlServerRequest *pRequestInfo,
2 void *pvParam, OVERLAPPED *pOverlapped) {
3 _ATLTRY {
4 (static_cast<IIsapiExtension*>(pvParam))->
5 DispatchStencilCall(pRequestInfo);
6 } _ATLCATCHALL() {
7 ATLASSERT(FALSE);
8 }
9}
A pointer to the CIsapiExtension object
is passed in via the pvParam parameter. The worker object
then turns around and calls back into the CIsapiExtension
via the DispatchStencilCall method. Why go back to the
CIsapiExtension instead of doing the work within the
worker class? The following chunk of the
DispatchStencilCall method reveals the answer:
1BOOL DispatchStencilCall(AtlServerRequest *pRequestInfo) {
2 ...
3 HTTP_CODE hcErr = HTTP_SUCCESS;
4 if (pRequestInfo->dwRequestState == ATLSRV_STATE_BEGIN) {
5 BOOL bAllowCaching = TRUE;
6 if (TransmitFromCache(pRequestInfo, &bAllowCaching)) {
7 return TRUE;
8 }
9 ...
10 }
11 ...
12}
The results of processing the SRF file are stored in a cache and are regenerated only when needed. The cache is stored in the ISAPI extension object so that it is available to all the worker threads.
The DispatchStencilCall method takes
care of the details of the various states in which a request can
be. The request eventually ends up at a new instance of your
request-handler object, and that’s where we go next.
Request Handlers
All request handlers derive from the
CRequestHandlerT template:
1template < class THandler,
2 class ThreadModel=CComSingleThreadModel,
3 class TagReplacerType=CHtmlTagReplacer<THandler> >
4class CRequestHandlerT :
5 public TagReplacerType,
6 public CComObjectRootEx<ThreadModel>,
7 public IRequestHandlerImpl<THandler> {
8public:
9 // public CRequestHandlerT members
10 CHttpResponse m_HttpResponse;
11 CHttpRequest m_HttpRequest;
12 ATLSRV_REQUESTTYPE m_dwRequestType;
13 AtlServerRequest* m_pRequestInfo;
14
15 CRequestHandlerT() ;
16 ~CRequestHandlerT() ;
17
18 void ClearResponse() ;
19
20 // Where user initialization should take place
21 HTTP_CODE ValidateAndExchange();
22
23 // Where user Uninitialization should take place
24 HTTP_CODE Uninitialize(HTTP_CODE hcError);
25
26 // HandleRequest is called to perform default processing
27 // of HTTP requests. Users can override this function in
28 // their derived classes if they need to perform specific
29 // initialization prior to processing this request or
30 // want to change the way the request is processed.
31 HTTP_CODE HandleRequest(
32 AtlServerRequest *pRequestInfo,
33 IServiceProvider* /*pServiceProvider*/);
34
35 HTTP_CODE ServerTransferRequest(LPCSTR szRequest,
36 bool bContinueAfterTransfer=false,
37 WORD nCodePage = 0, CStencilState *pState = NULL);
38
39 ...
40}
The CRequestHandlerT class provides the
m_HttpRequest object as a way of accessing the request
data, and the m_HttpResponse object that is used to build
the response to go back to the client. The previous code block
shows some of the more useful methods of this class. Some, such as
ServerTransferRequest, are available for you to call from
your request handler. Others, such as ValidateAndExchange,
exist to be overridden in your derived class.
The actual processing of
the stencil file is handled via the TagReplacerType
template parameter, which defaults to ChtmlTagReplacer.
This class is itself a template:
1template <class THandler, class StencilType=CHtmlStencil>
2class CHtmlTagReplacer :
3 public ITagReplacerImpl<THandler>
4{ ... }
There’s also a second layer of templates here.
The CHtmlTagReplacer actually exists to manage the stencil
cache. For each .srf file, a stencil object is created the
first time. The .srf file is then parsed into a series of
StencilToken objects, which are stored in an array in the
stencil object. Rendering the HTML is done by walking the array and
rendering each token. That stencil object is then stored in the
cache for later use. This way the parsing is done only once.
By default, the type of stencil object created
is CHtmlStencil. This class knows about all the
replacement tags that can occur in .srf files. However, it
is a template parameter and, as such, can be overridden to add new
replacement tags. This is your opportunity to customize the stencil
replacement system: Create a new stencil class (which should derive
from CStencil) and override the parsing methods to add new
tags to the processing.
An Example Request Handler
Let’s see how this comes together. Here’s an
example .srf file that’s part of a simple online
forum [2] system, to provide a list of forums
available:
1<html>
2{{handler SimpleForums.dll/ForumList}}
3<head>
4 <title>Forums</title>
5</head>
6<body>
7<h1>ATL Server Simple Forums</h1>
8<p>There are {{NumForums}} forums on this system.</p>
9{{while MoreForums}}
10 <h2><a href="{{LinkToForum}}">{{ForumName}}</a></h2>
11 <p>{{ForumDescription}}</p>
12 <p><a href="{{LinkToEditForum}}">Edit Forum Settings</a></p>
13 <br />
14{{NextForum}}
15{{endwhile}}
16</body>
17</html>
This file uses not only the {{handler}}
directive, but also textual replacements and the {{while}}
loop.
So, we need a forum list handler. The handler class looks like this: [3]
1class ForumListHandler :
2 public CRequestHandlerT<ForumListHandler> {
3public:
4 ForumListHandler(void);
5public:
6 virtual ~ForumListHandler(void);
7
8public:
9BEGIN_REPLACEMENT_METHOD_MAP(ForumListHandler)
10 REPLACEMENT_METHOD_ENTRY("NumForums", OnNumForums)
11 REPLACEMENT_METHOD_ENTRY("MoreForums", OnMoreForums)
12 REPLACEMENT_METHOD_ENTRY("NextForum", OnNextForum)
13 REPLACEMENT_METHOD_ENTRY("ForumName", OnForumName)
14 REPLACEMENT_METHOD_ENTRY("ForumDescription",
15 OnForumDescription)
16 REPLACEMENT_METHOD_ENTRY("LinkToForum", OnLinkToForum)
17 REPLACEMENT_METHOD_ENTRY("LinkToEditForum",
18 OnLinkToEditForum)
19END_REPLACEMENT_METHOD_MAP()
20
21 HTTP_CODE ValidateAndExchange();
22
23private:
24
25 HTTP_CODE OnNumForums( );
26 HTTP_CODE OnMoreForums( );
27 HTTP_CODE OnNextForum( );
28 HTTP_CODE OnForumName( );
29 HTTP_CODE OnLinkToForum( );
30 HTTP_CODE OnLinkToEditForum( );
31 HTTP_CODE OnForumDescription( );
32
33private:
34
35 ForumList m_forums;
36 CComPtr< _Recordset > m_forumsRecordSet;
37};
The action starts for
this class in the ValidateAndExchange method, which is
called at the start of processing after the m_HttpRequest
variable has been created.
1#define AS_HR(ex) { \
2 HRESULT_hr = ex; if(FAILED(_hr)) { return HTTP_FAIL; } }
3HTTP_CODE ForumListHandler::ValidateAndExchange() {
4 // Set the content-type
5 m_HttpResponse.SetContentType("text/html");
6
7 AS_HR( m_forums.Open( ) );
8 AS_HR( m_forums.ReadAllForums( &m_forumsRecordSet ) );
9
10 return HTTP_SUCCESS;
11}
The return value, HTTP_CODE, is used to
signal what HTTP return code to send back to the client. If this
function returns HTTP_SUCCESS, the processing continues.
On the other hand, if something is wrong, you can return a
different value (such as HTTP_FAIL) to abort the
processing and send an HTTP failure code back to the browser.
The HTTP_CODE type is actually a
typedef for a DWORD, and it packs multiple data items into
those 32 bits (much like hrESULT does). The high 16 bits
contain the HTTP status code that should be returned. The lower 16
bits specify a code to tell IIS what to do with the rest of the
request. Take a look at MSDN for the set of predefined
HTTP_CODE macros.
In this example, we use the data layer object in
the m_forums variable to go out to our forums database and
read the list of forums. Assuming that this worked, [4] we
store the list (an ADO recordset) as a member variable.
The replacement functions
come in two varieties: textual replacement and flow control. The
OnForumName method is an example of the former. When the
{{ForumName}} token is found in the SRF file, this code is
run:
1HTTP_CODE ForumListHandler::OnForumName( ) {
2 CComBSTR name;
3 AS_HR( m_forums.GetCurrentForumName( m_forumsRecordSet,
4 &name ) );
5 m_HttpResponse << CW2A( name );
6 return HTTP_SUCCESS;
7}
Here, the m_HttpResponse member is used
like a C++ stream class to output the name of the current forum.
The CW2A conversion class is used because our data layer
is returning Unicode, but the SRF file defaults to 8-bit
characters.
The flow-control tokens use the same replacement map but work very differently. Within the replacement method, the return value is the important thing:
1HTTP_CODE ForumListHandler::OnMoreForums( ) {
2 VARIANT_BOOL endOfRecordSet;
3 AS_HR( m_forumsRecordSet->get_adoEOF( &endOfRecordSet ) );
4 if( endOfRecordSet == VARIANT_TRUE ) {
5 return HTTP_S_FALSE;
6 }
7 return HTTP_SUCCESS;
8}
Here, we’re checking to see if we have any more
records in our recordset. If so, we return HTTP_SUCCESS.
If not, we return HTTP_S_FALSE. Much like S_FALSE
is the “Succeeded, but false” hrESULT,
HTTP_S_FALSE signals the stencil processor that the
Boolean expression being evaluated is false, but the processing
completed. In this case, the false return value causes the
while loop to exit.
Handling Input
Let’s get a little further into our example and look at how to process input. Consider this HTML form used to create or edit a forum in our system:
1<html>
2{{handler SimpleForums.dll/EditForum}}
3 <head>
4 <title>Edit Forum</title>
5 </head>
6 <body>
7 <h1>Edit Forum Information</h1>
8 {{if ValidForumId}}
9 <form action="editforum.srf?forumid={{ForumId}}"
10 method="post">
11 <table border="0" cellpadding="0">
12 <tr>
13 <td>
14 Forum Name:
15 </td>
16 <td>
17 <input type="text" name="forumName" id="forumName"
18 maxlength="63" value="{{ForumName}}" />
19 </td>
20 </tr>
21 <tr>
22 <td>
23 Forum Description:
24 </td>
25 <td>
26 <textarea cols="50" rows="10" wrap="soft"
27 id="forumDescription">
28 {{ForumDescription}}
29 </textarea>
30 </td>
31 </tr>
32 </table>
33 <input type="submit" />
34 <a href="forumlist.srf">Return to Forum List</a>
35 </form>
36 {{else}}
37 <p><b>You have given an invalid forum ID.
38 Shame on you!</b></p>
39 {{endif}}
40 </body>
41</html>
Here we’re using both the standard ways to do
input in HTML: The browser query string contains the forum ID that
we’re editing, and the post variables contain the new text and
descriptions. ATL Server provides access to both of these via the
m_HttpRequest object. This object is of the class
CHttpRequest and provides a variety of ways to get access
to server, query string, and form variables:
1class CHttpRequest : public IHttpRequestLookup {
2public:
3
4 // Access to Query String parameters as a collection
5 const CHttpRequestParams& GetQueryParams() const;
6
7 // Access to Query String parameters via an iterator
8 POSITION GetFirstQueryParam(LPCSTR *ppszName,
9 LPCSTR *ppszValue);
10 POSITION GetNextQueryParam(POSITION pos,
11 LPCSTR *ppszName, LPCSTR *ppszValue);
12
13 // Get the entire raw query string
14 LPCSTR GetQueryString();
15
16 // Access to form variables as a collection
17 const CHttpRequestParams& GetFormVars() const;
18
19 // Access to form variables via an iterator
20 POSITION GetFirstFormVar(LPCSTR *ppszName,
21 LPCSTR *ppszValue);
22 POSITION GetNextFormVar(POSITION pos,
23 LPCSTR *ppszName, LPCSTR *ppszValue);
24
25 // Access to uploaded files
26 POSITION GetFirstFile(LPCSTR *ppszName,
27 IHttpFile **ppFile);
28 POSITION GetNextFile(POSITION pos,
29 LPCSTR *ppszName, IHttpFile **ppFile);
30
31 // Get all cookies as a string
32 BOOL GetCookies(LPSTR szBuf,LPDWORD pdwSize);
33 BOOL GetCookies(CStringA& strBuff);
34
35 // Get a single cookie by name
36 const CCookie& Cookies(LPCSTR szName);
37
38 // Access cookies via an iterator
39 POSITION GetFirstCookie(LPCSTR *ppszName,
40 const CCookie **ppCookie);
41 POSITION GetNextCookie(POSITION pos,
42 LPCSTR *ppszName, const CCookie **ppCookie);
43
44 // Get the session cookie
45 const CCookie& GetSessionCookie();
46
47 // Get the HTTP method used for this request
48 LPCSTR GetMethodString();
49 HTTP_METHOD GetMethod();
50
51 // Access to various server variables and HTTP Headers
52 LPCSTR GetContentType();
53
54 BOOL GetAuthUserName(LPSTR szBuff, DWORD *pdwSize);
55 BOOL GetAuthUserName(CStringA &str);
56
57 BOOL GetPhysicalPath(LPSTR szBuff, DWORD *pdwSize);
58 BOOL GetPhysicalPath(CStringA &str);
59
60 BOOL GetAuthUserPassword(LPSTR szBuff, DWORD *pdwSize);
61 BOOL GetAuthUserPassword(CStringA &str);
62
63 BOOL GetUrl(LPSTR szBuff, DWORD *pdwSize);
64 BOOL GetUrl(CStringA &str);
65
66 BOOL GetUserHostName(LPSTR szBuff, DWORD *pdwSize);
67 BOOL GetUserHostName(CStringA &str);
68
69 BOOL GetUserHostAddress(LPSTR szBuff, DWORD *pdwSize);
70 BOOL GetUserHostAddress(CStringA &str);
71
72 LPCSTR GetScriptPathTranslated();
73 LPCSTR GetPathTranslated();
74 LPCSTR GetPathInfo();
75
76 BOOL GetAuthenticated();
77
78 BOOL GetAuthenticationType(LPSTR szBuff, DWORD *pdwSize);
79 BOOL GetAuthenticationType(CStringA &str);
80
81 BOOL GetUserName(LPSTR szBuff, DWORD *pdwSize);
82 BOOL GetUserName(CStringA &str);
83
84 BOOL GetUserAgent(LPSTR szBuff, DWORD *pdwSize);
85 BOOL GetUserAgent(CStringA &str);
86
87 BOOL GetUserLanguages(LPSTR szBuff, DWORD *pdwSize);
88 BOOL GetUserLanguages(CStringA &str);
89 BOOL GetAcceptTypes(LPSTR szBuff,DWORD *pdwSize);
90 BOOL GetAcceptTypes(CStringA &str);
91
92 BOOL GetAcceptEncodings(LPSTR szBuff, DWORD *pdwSize);
93 BOOL GetAcceptEncodings(CStringA& str);
94
95 BOOL GetUrlReferer(LPSTR szBuff, DWORD *pdwSize);
96 BOOL GetUrlReferer(CStringA &str);
97
98 BOOL GetScriptName(LPSTR szBuff, DWORD *pdwSize);
99 BOOL GetScriptName(CStringA &str);
100
101 // Raw access to server variables
102 BOOL GetServerVariable(LPCSTR szVariable, CStringA &str) const;
103
104}; // class CHttpRequest
For methods that return strings (that is, almost
all of them), there are two overloads. The first one is the
traditional “pass in a buffer and a DWORD containing the
buffer length” style used so often in the Win32 API. The second
overload lets you pass in a CStringA reference and stores
the resulting string in the CString. The latter overload
is much more convenient; the former gives you complete control over
memory allocation if you need it for performance.
The query string and form variable access
methods give you a variety of ways to get at the contents of these
two collections of variables. For query strings, the easiest way to
work if you know what query strings you’re expecting is to use the
GetQueryParams() method. This returns a reference to a
CHttpRequestParams object. This object basically maps
name/value pairs and is used to access the contents of the query
strings. Usage is quite simple:
1const CHttpRequestParams& queryParams =
2 m_HttpRequest.GetQueryParams( );
3CStringA cstrForumId = queryParams.Lookup( "forumid" );
If the query parameter you’re looking for isn’t present, you get back an empty string.
The CHttpRequestParams object also
supports an iterator interface to walk the list of name/value pairs
in the collection. Unfortunately, this is an MFC-style iterator
rather than a standard C++ iterator. Here’s an example that walks
the list of form variables submitted in a post:
1HTTP_CODE EditForumHandler::OnFormFields( ) {
2 if( m_HttpRequest.GetMethod( ) ==
3 CHttpRequest::HTTP_METHOD_POST ) {
4 const CHttpRequestParams &formFields =
5 m_HttpRequest.GetFormVars( );
6 POSITION pos = formFields.GetStartPosition( );
7 m_HttpResponse << "Form fields:<br>" << "<ul>";
8
9 const CHttpRequestParams::CPair *pField;
10 for( pField = formFields.GetNext( pos );
11 pField != 0;
12 pField = formFields.GetNext( pos ) ) {
13 m_HttpResponse << "<li>" << pField->m_key <<
14 ": " << pField->m_value << "</li>";
15 }
16 m_HttpResponse << "</ul>";
17 }
18 return HTTP_SUCCESS;
19}
To use the iterator interface, you call the
GetStartPosition( ) method on the collection to get back a
POSITION object. This acts as a pointer into the
collection and is initialized to one before the first element in
the collection. The GetNext( ) method increments the
POSITION to point to the next item in the collection and
returns a pointer to the object at the new POSITION. When
you get to the end, GetNext( ) returns 0.
Because the CHttpRequestParams class
stores name/value pairs, it makes sense that the GetNext()
call returns a CPair object; this is a nested type defined
within the map class. It has two fields: m_key and
m_value, which should be self-explanatory.
It’s up to you to choose which way to access
your inputs. The Lookup method is much more convenient
when you know in advance what form fields or query string
parameters you’re expecting. The iterator versions are useful if
you can have a wide variety of inputs and don’t know in advance
what you’re going to get (for example, some blog systems enable you
to pass a variety of different parameters to bring up a single
post, all posts in a month, or posts from a start/end date).
One thing to consider is what to do about parameters you don’t expect and don’t support. The easiest thing to do is simply ignore them. However, if somebody is sending you unexpected junk, it might be somebody trying to hack your system, so you might want to at least loop through the query string and form variables to check if there’s anything in there you don’t expect. Your response to these values is up to you: This could range from ignoring them to logging the invalid parameters or failing the request outright.
Data Exchange and Validation
So
we have easy access to our query string and form variables, but
that access is less than convenient. We need to check for empty
strings when calling the Lookup() method to verify that
the variable exists at all. We need to do data type conversions: In
our example, the forum ID is an integer, but in the query string
it’s stored as a string. And when we’ve got the value, we need to
do validation on it: Faulty input validation is the single biggest
security flaw in web sites today. [5]
ATL Server includes some common validation and
data-conversion functions to make life easier for the web
developer. This is implemented via the CValidateObject< > template and the CValidateContext class.
The CValidateObject< > template
is designed to be used as a base class; the
CHttpRequestParams class derives from
CValidateObject< >. It provides numerous overloads
of two methods: Exchange and Validate:
1template <class TLookupClass, class TValidator = CAtlValidator>
2class CValidateObject {
3public:
4 template <class T>
5 DWORD Exchange(
6 LPCSTR szParam,
7 T* pValue,
8 CValidateContext *pContext = NULL) const;
9
10 template<>
11 DWORD Exchange(
12 LPCSTR szParam,
13 CString* pstrValue,
14 CValidateContext *pContext) const;
15
16 template<>
17 DWORD Exchange(
18 LPCSTR szParam,
19 LPCSTR* ppszValue,
20 CValidateContext *pContext) const;
21
22 template<>
23 DWORD Exchange(
24 LPCSTR szParam,
25 GUID* pValue,
26 CValidateContext *pContext) const;
27
28 template<>
29 DWORD Exchange(
30 LPCSTR szParam,
31 bool* pbValue,
32 CValidateContext *pContext) const;
33
34
35 template <class T, class TCompType>
36 DWORD Validate(
37 LPCSTR Param,
38 T *pValue,
39 TCompType nMinValue,
40 TCompType nMaxValue,
41 CValidateContext *pContext = NULL) const;
42
43 template<>
44 DWORD Validate(
45 LPCSTR Param,
46 LPCSTR* ppszValue,
47 int nMinChars,
48 int nMaxChars,
49 CValidateContext *pContext) const;
50
51 template<>
52 DWORD Validate(
53 LPCSTR Param,
54 CString* pstrValue,
55 int nMinChars,
56 int nMaxChars,
57 CValidateContext *pContext) const;
58
59 template<>
60 DWORD Validate(
61 LPCSTR Param,
62 double* pdblValue,
63 double dblMinValue,
64 double dblMaxValue,
65 CValidateContext *pContext) const;
66};
The
Exchange( ) method takes in the name of a variable. If
that variable exists in the collection you’re using, it converts
the string to the correct type (based on the type T you
use) and stores the result in the requested pointer. The return
value tells you whether the parameter was present:
1HTTP_CODE ValidateAndExchange( ) {
2 ...
3 int forumId;
4 m_HttpRequest.GetQueryParams().Exchange( "forumid",
5 &forumId, NULL );
6 ...
7}
Thanks to the wonder of
template type inference, by passing in the address of a variable of
type int, the Exchange method knows that I want
the string converted to type int. The Exchange( )
method properly works with these types: ULONGLONG,
LONGLONG, double, int, unsigned
int, long, unsigned long,
short, and unsigned short. In addition, there are
specializations for CString and LPCSTR, GUID, and
bool.
This is a convenient way to check whether a
parameter exists, copy it, and do data conversion all in one fell
swoop. But that’s usually not enough. You generally need to do more
checking than “Is it an int?” The Validate( ) method and
the various overloads give you some more checking. Specifically,
when working with a numeric value, Validate lets you check
that a parameter is within a particular numeric range. When
validating strings, the Validate method can check for
minimum and maximum string lengths (very helpful to avoid buffer
overflows). For example, here’s some code from the
ValidateAndExchange method that checks the results of our
form post:
1HTTP_CODE ValidateAndExchange( ) {
2 ...
3 if( m_HttpRequest.GetMethod( ) ==
4 CHttpRequest::HTTP_METHOD_POST ) {
5 const CHttpRequestParams& formFields =
6 m_HttpRequest.GetFormVars( );
7 formFields.Validate( "forumName", &m_forumName,
8 1, 50, &m_validationContext );
9 formFields.Validate( "forumDescription",
10 &m_forumDescription, 1, 255, &m_validationContext );
11 }
12 ...
13}
Notice that I’m not actually checking the return
values from the Validate method. That’s one way to get the
results of the Validate call, but having to do this
repeatedly for every field gets tedious (and hard to maintain)
quickly:
1if( VALIDATION_SUCCEEDED( formFields.Validate(
2 "forumName", &m_forumName, 1, 50, &m_validationContext ) )
3{ ... }
Instead, we take advantage
of another class: CValidateContext. The last parameter for
the Exchange() and Validate() methods is an
optional pointer to a CValidateContext object. This object
acts as a collectionspecifically, a collection of validation
errors. If the Exchange() or Validate() call
fails, an entry in the CValidateContext object is made.
Using the validation context, you can do all your validation checks
and not have to worry about the results until the end.
The easiest thing to do is check whether there
were any validation failures, via the ParamsOK() method on
the CValidateContext object. You can also walk the list of
errors, like this:
1HTTP_CODE EditForumHandler::OnValidationErrors( ) {
2 if( m_validationContext.ParamsOK( ) ) {
3 m_HttpResponse << "No validation errors occurred";
4 }
5 else {
6 int numValidationFailures =
7 m_validationContext.GetResultCount( );
8 m_HttpResponse << "<ol>";
9 for( int i = 0; i < numValidationFailures; ++i ) {
10 CStringA faultName;
11 DWORD faultCode;
12 m_validationContext.GetResultAt( i, faultName,
13 faultCode );
14 m_HttpResponse << "<li>" << faultName << ": " <<
15 faultCode << "</li>";
16 }
17 m_HttpResponse << "</ol>";
18 }
19 return HTTP_SUCCESS;
20}
Here we’re just printing the fault codes as integers. These are the possible fault codes:
VALIDATION_S_OK. The named value was found and could be converted successfully.VALIDATION_S_EMPTY. The name was present, but the value was empty.VALIDATION_E_PARAMNOTFOUND. The named value was not found.VALIDATION_E_INVALIDPARAM. The name was present, but the value could not be converted to the requested data type.VALIDATION_E_LENGTHMIN. The name was present and could be converted to the requested data type, but the value was too small.VALIDATION_E_LENGTHMAX. The name was present and could be converted to the requested data type, but the value was too large.VALIDATION_E_FAIL. An unspecified error occurred.
It would have been nice if these were just
custom hrESULT values, but, unfortunately, they’re not.
Luckily, there’s also a VALIDATION_SUCCEEDED macro that
tells you whether a particular error code is a success.
When validation for a particular variable fails,
the Validate (or Exchange) method adds a
name/value pair to the validation context. The name is the name of
the variable that failed. The value is the fault code. These can be
retrieved using the GetresultAt method, as shown earlier.
You are also free to add your own error records to the validation
context via the AddResult method. For example, we use the
Exchange method to find out whether there’s a
forumid, but we still need to see if it’s valid:
1void EditForumHandler::ValidateLegalForumId( ){
2 if( m_forumId != -1 ) {
3 if( SUCCEEDED( m_forumList.ReadOneForum(
4 m_forumId, &m_forumRecordset ) ) ) {
5 bool containsData;
6 if( SUCCEEDED( m_forumList.ContainsForumData(
7 m_forumRecordset, &containsData ) ) ) {
8 if( !containsData ) {
9 m_validationContext.AddResult(
10 "forumid", VALIDATION_E_FAIL );
11 m_forumId = -1;
12 }
13 }
14 }
15 }
16}
In this case, I’m using a generic
VALIDATION_E_FAIL code, but there’s no reason you can’t
make up your own DWORD error-validation codes.
If you have multiple records with the same name,
only the last one in is recorded. So, if you check the same value
multiple times, as we do with forumid, be aware that later
validation failures could overwrite earlier records in the
context.
The CValidateContext class gives you
several options when adding records to the collection:
1class CValidateContext {
2public:
3 enum { ATL_EMPTY_PARAMS_ARE_FAILURES = 0x00000001 };
4
5 CValidateContext(DWORD dwFlags=0);
6 bool AddResult(LPCSTR szName, DWORD type,
7 bool bOnlyFailures = true);
8
9 ...
10};
When constructing the CValidateContext
object, by default, empty parameters (ones that were in the request
but have no data) are not considered an error by the
CValidateContext. If you specify the
ATL_EMPTY_PARAMS_ARE_FAILURES flag when constructing the
context, empty parameters are treated as errors. In addition, you
can pass a third, optional parameter to the AddResult
method. If true (the default), the context ignores records
that have the fault code VALIDATION_S_OK or
VALIDATION_S_EMPTY (although the latter is ignored only if
empty parameters are not errors). This optional parameter is useful
when you call AddResult yourself; Validate and
Exchange never pass false for this parameter.
When validation fails, you generally want to
display something to the user. Nothing is built into ATL Server,
but it’s easy enough to display errors on your own. Here’s the
.srf file for my “edit forum” page:
1<html>
2{{handler SimpleForums.dll/EditForum}}
3 <head>
4 <title>Edit Forum</title>
5 </head>
6 <body>
7 <h1>Edit Forum Information</h1>
8 {{if ValidForumId}}
9 <form action="editforum.srf?forumid={{ForumId}}"
10 method="post">
11 <table border="0" cellpadding="0">
12 <tr>
13 <td>
14 Forum Name:
15 </td>
16 <td>
17 <input type="text" name="forumName"
18 id="forumName" maxlength="63"
19 value="{{ForumName}}" />
20 </td>
21 </tr>
22 <tr>
23 <td>
24 Forum Description:
25 </td>
26 <td>
27 <textarea cols="50" rows="10"
28 wrap="soft" name="forumDescription"
29 id="forumDescription">
30 {{ForumDescription}}
31 </textarea>
32 </td>
33 </tr>
34 </table>
35 <input type="submit" />
36 <a href="forumlist.srf">Return to Forum List</a>
37 </form>
38 {{else}}
39 <p><b>You have given an invalid forum ID. Shame on you!</b>
40 {{endif}}
41 {{FormFields}}
42 {{ValidationErrors}}
43 </body>
44</html>
The ValidationErrors substitution is
handled by the OnValidationErrors method, which walks the
validation context and outputs both the fields that have errors and
the error code:
1HTTP_CODE EditForumHandler::OnValidationErrors( ) {
2 if( m_validationContext.ParamsOK( ) ) {
3 m_HttpResponse << "No validation errors occurred";
4 }
5 else {
6 m_HttpResponse << "Validation Errors:";
7 int numValidationFailures =
8 m_validationContext.GetResultCount( );
9 m_HttpResponse << "<ol>";
10 for( int i = 0; i < numValidationFailures; ++i ) {
11 CStringA faultName;
12 DWORD faultCode;
13 m_validationContext.GetResultAt( i, faultName,
14 faultCode );
15 m_HttpResponse << "<li>" << faultName <<
16 ": " << FaultCodeToString(faultCode) << "</li>";
17 }
18 m_HttpResponse << "</ol>";
19 }
20 return HTTP_SUCCESS;
21}
22CStringA EditForumHandler::FaultCodeToString(DWORD faultCode) {
23 switch(faultCode) {
24 case VALIDATION_S_OK:
25 return "Validation succeeded";
26
27 case VALIDATION_S_EMPTY:
28 return "Name present but contents were empty";
29
30 case VALIDATION_E_PARAMNOTFOUND:
31 return "The named value was not found";
32
33 case VALIDATION_E_LENGTHMIN:
34 return "Value was present and converted, but too small";
35 case VALIDATION_E_LENGTHMAX:
36 return "Value was present and converted, but too large";
37
38 case VALIDATION_E_INVALIDLENGTH:
39 return "(Unused error code)";
40
41 case VALIDATION_E_INVALIDPARAM:
42 return "The value was present but could not be "
43 "converted to the given data type";
44
45 case VALIDATION_E_FAIL:
46 return "Validation failed";
47
48 default:
49 return "Unknown validation failure code";
50 }
51}
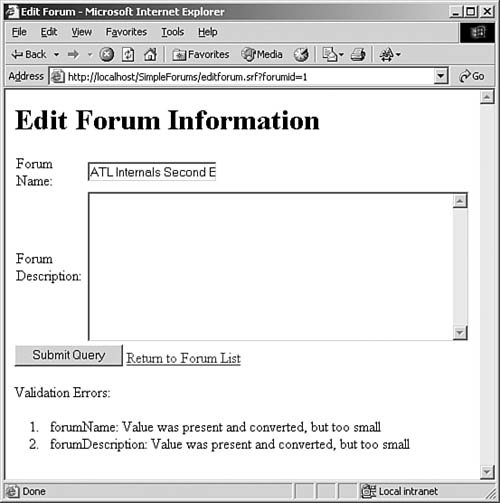
This code simply walks through the validation context and displays the names of the failures (usually the field names) and the failure code, converted to a string. Figure 14.2 shows the results of validation failures. The fields in question weren’t long enough to pass validation (because they need to be at least 1 character).
Figure 14.2. Results of validation failure
![[View full size image]](_static/images/14atl02_alt.jpg){kind=link}
A small bug in the
validation functions makes the
ATL_EMPTY_PARAMS_ARE_FAILURES flag essential. The problem
comes in when you have a post variable with an empty string. For
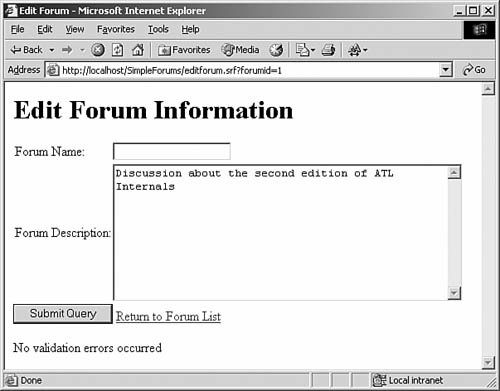
example, Figure 14.3 shows
our forum edit form; I cleared the forum name before clicking
Submit.
Figure 14.3. Edit Forum page with no forum name
![[View full size image]](_static/images/14atl03_alt.jpg){kind=link}
When I click the Submit Query button, the
forumName text field gets sent back in the HTTP post, but
with no value. In the ValidateAndExchange method, we make
use of ATL Server’s validation functions to check our input:
1HTTP_CODE EditForumHandler::ValidatePost( ) {
2 ...
3 if( m_HttpRequest.GetMethod( ) ==
4 CHttpRequest::HTTP_METHOD_POST ) {
5 const CHttpRequestParams& formFields =
6 m_HttpRequest.GetFormVars( );
7 formFields.Validate( "forumName", &m_forumName,
8 1, 50, &m_validationContext );
9 }
10
11 return HTTP_SUCCESS;
12}
The intention here is to require that the
forumName variable exists and that it be from 1 to 50
characters in length. If we check the ParamsOK variable,
it correctly returns false: The forumName variable is not
within 1 and 50 characters in length. However, if we walk the list
of errors in the validation context, there will be no record for
the forumName field. What’s going on here?
Let’s take a look at the code for
CValidateObject::Validate for strings:
1template<>
2DWORD Validate(
3 LPCSTR Param,
4 LPCSTR* ppszValue,
5 int nMinChars,
6 int nMaxChars,
7 CValidateContext *pContext) const {
8 LPCSTR pszValue = NULL;
9 DWORD dwRet = Exchange(Param, &pszValue, pContext);
10
11 if (dwRet == VALIDATION_S_OK ) {
12 if (ppszValue)
13 *ppszValue = pszValue;
14 dwRet = TValidator::Validate(pszValue, nMinChars, nMaxChars);
15 if (pContext && dwRet != VALIDATION_S_OK)
16 pContext->AddResult(Param, dwRet);
17 }
18 else if (dwRet == VALIDATION_S_EMPTY && nMinChars > 0) {
19 dwRet = VALIDATION_E_LENGTHMIN;
20 if (pContext) {
21 pContext->SetResultAt(Param, VALIDATION_E_LENGTHMIN);
22 }
23 }
24 return dwRet;
25}
The two lines in bold are
where the record is added to the validation context. Note that the
first one calls the AddResult method. This is where we
check for validation failures. Notice the second one: This code
executes if the validation result is VALIDATION_S_EMPTY,
and there’s a minimum character length on the string. In this case,
it calls the SetResultAt method on the validation context
instead, using the name of the parameter.
Here’s where the bug comes in. Let’s look at the
SetResultAt implementation:
1class CValidateContext {
2public:
3
4 bool SetResultAt(__in LPCSTR szName, __in DWORD type) {
5 _ATLTRY {
6 if (!VALIDATION_SUCCEEDED(type) ||
7 (type == VALIDATION_S_EMPTY &&
8 (m_dwFlags & ATL_EMPTY_PARAMS_ARE_FAILURES))) {
9 m_bFailures = true;
10 }
11
12 return TRUE == m_results.SetAt(szName,type);
13 }
14 _ATLCATCHALL() { }
15
16 return false;
17 }
18
19 // Returns true if there are no validation failures
20 // in the collection, returns false otherwise.
21 __checkReturn bool ParamsOK() {
22 return !m_bFailures;
23 }
24
25protected:
26 CSimpleMap<CStringA, DWORD> m_results;
27 bool m_bFailures;
28}; // CValidateContext
The
SetResultAt call sets the m_bFailures flag, which
is used by the ParamsOK method, and then calls
m_results.SetAt. And here’s the source of the problem:
CSimpleMap::SetAt sets the value only if the name you’re
using is already in the map. If
the key isn’t in the map, SetAt silently fails.
So what happens here is that, because an empty
parameter isn’t an error by default, it doesn’t get added to the
context in the AddResult call. Then, when the
minimum-length validation fails, the call to SetResultAt
TRies to add using the SetAt call. But that fails because
the parameter isn’t already in the m_results map. As a
result, the m_bFailures flag is set, but there’s no actual
record of the specific failure.
You can work around this bug in two ways. The
first is to set the ATL_EMPTY_PARAMS_ARE_FAILURES flag
when you create your validation-context object. This is best if you
absolutely must have a value in the parameter in question. The
other option is best used if the parameter is actually optional. In
this case, be sure to set the minimum length in the
Validate call to 0 instead of 1, as I
did earlier.
Regular Expressions
Dealing with numeric values is made quite easy
by the Validate() method, but for strings, you often need
to do a lot more than just check for the maximum length. It’s good
security practice to enforce that your input contains only a known
set of good characters, for example. Or what if you need to receive
dates in a particular format? None of the Validate
overrides helps you there.
The typical tool used in these kinds of string validation is the regular expression. UNIX programmers have been using them for years; one could argue that the popularity of the Perl programming language is mainly because of the ease of regular expression matching. Luckily, ATL Server provides a regular expression engine that we can use from the comfort of good old C++.
Unfortunately, a discussion of regular expression syntax and how to use regular expressions is beyond the scope of this book; see the documentation for details. [6]
Regular expressions are done in ATL Server via
the CAtlRegExp class:
1template <class CharTraits /* =CAtlRECharTraits */>
2class CAtlRegExp {
3public:
4 CAtlRegExp();
5
6 typedef typename CharTraits::RECHARTYPE RECHAR;
7
8 REParseError Parse(const RECHAR *szRE,
9 BOOL bCaseSensitive=TRUE);
10
11 BOOL Match(const RECHAR *szIn,
12 CAtlREMatchContext<CharTraits> *pContext,
13 const RECHAR **ppszEnd=NULL);
14};
The usage is fairly simple. For example, suppose we wanted to ensure that the forum name contains only alphabetical characters, spaces, and commas. The following does the trick:
1void EditForumHandler::ValidateLegalForumName( ) {
2 CAtlRegExp< CAtlRECharTraitsW > re;
3 CAtlREMatchContext< CAtlRECharTraitsW > match;
4
5 ATLVERIFY( re.Parse( L"^[a-zA-Z,]*$" ) ==
6 REPARSE_ERROR_OK );
7 if( !re.Match( m_forumName.GetBuffer( ), &match ) ) {
8 m_validationContext.AddResult( "forumName",
9 VALIDATION_E_FAIL );
10 }
11}
First, you create the CAtlRegExp
object. The template parameter is a traits class that defines various properties
of the character set that the regular expression engine will be
searching. ATL defines three of these traits classes:
CAtlRECharTraitsA (for ANSI characters),
CAtlRECharTraitsMB (for multibyte strings) and
CAtlRECharTraitsW (for wide character strings). These
traits classes are used much like the traits classes are in the
CString class as discussed in Chapter 2, “Strings and Text.”
After you’ve created the regex object, you need
to feed in a regular expression by calling the Parse
method. This method returns a value of type REParseError.
REPARSE_ERROR_OK means that everything was fine; any other
return code indicates a syntax error in the regular express. The
documentation for CAtlRegExp::Parse gives the complete
list of possible error codes.
Next, you create an object of type
CAtlREMatchContext, which takes the same character traits
template parameter as the regexp object did. Then, you call the
Match method on the regular expression object, passing in
the string to search and the match context object. Match
returns true if the regular expression matched the string,
and false if it did not. In some cases, this is all we
need to know. In others, we might want to know more about what
specifically matched. This information is stored in the match
context object. The documentation and sample code give many
examples on how to use the match context and more information about
what you can do with regular expressions.
Session Management
The scalability of the Web comes directly from its stateless nature. As far as the web server is concerned, every HTTP request is independent. The stateless architecture means that server farms and load balancing are easy, caching can be added at many different places, and it’s easy to add hardware to an existing system.
It also makes writing a shopping cart a real pain in the neck.
Nearly every web application needs to deal with state management. State can be on a per-session basis, a per-application basis, or a per-page basis. When thinking about state management, some standard questions need to be answered:
What’s the scope? From where is the state data available, and what’s its lifetime?
Where’s the data stored? In memory? In a database? In a disk file? In a hidden form field?
How do we find the state when processing a particular request?
One of the more difficult state-management pieces to build by hand is session state: per-user data that persists across HTTP request. Luckily for us, ATL Server, like all other serious web frameworks, provides a session-state service so we don’t have to roll our own.
Using Session State
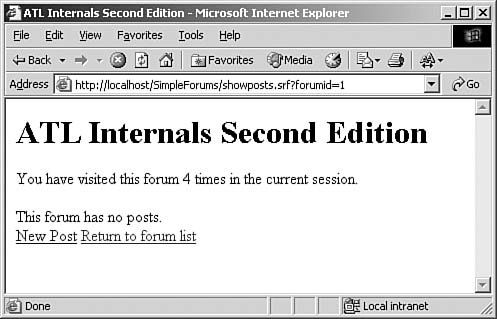
Before diving into the internals, let’s take a quick look at how to use session state. In our ongoing forum example, I want to add a hit counter to each forum’s page, so I can see how often I’ve gone to the page. It looks something like Figure 14.4.
Figure 14.4. Forum page with a hit counter
The .srf file
for this page is pretty simple:
1<html>
2{{handler SimpleForums.dll/ShowPosts}}
3<head>
4<title>{{ForumName}}</title>
5</head>
6<body>
7<h1>{{ForumName}}</h1>
8<p>You have visited this forum {{HitCount}} times in the
9current session.</p>
10<div>
11<! ... Post List content removed for clarity >
12</div>
13<a href="newpost.srf?forumid={{ForumId}}">New Post</a>
14<a href="forumlist.srf">Return to forum list</a>
15{{endif}}
16</body>
17</html>
The trick is, how do we implement the
HitCount replacement? We want the hit counter to stick
around between page views; as the user moves from forum to forum on
the site, we want each page’s hit count to be independent and
persistence.
Unlike classic ASP and ASP.NET, ATL Server does not automatically create a session for you. In the C++ tradition of “don’t pay for what you don’t use,” you must explicitly create a session object when you need it.
Getting the Session Service
The first thing you need to do is get hold of an
ISessionStateService interface pointer. This interface
provides the capability to create and retrieve sessions. The object
is available in your request handler via the
m_spServiceProvider member that is inherited from
CRequestHandlerT< >. In your
ValidateAndExchange function, do something like this:
1ShowPostsHandler.h:
2
3class ShowPostsHandler :
4 public CRequestHandlerT< ShowPostsHandler > {
5...
6private:
7...
8 CComPtr< ISessionStateService > m_spSessionStateSvc;
9 CComPtr< ISession > m_spSession;
10};
11
12ShowPostsHandler.cpp:
13
14HTTP_CODE ShowPostsHandler::ValidateAndExchange( ) {
15 if( FAILED( m_spServiceProvicer->QueryService(
16 __uuidof(ISessionStateService), &m_spSessionStateSvc ) ) ) {
17 return HTTP_FAIL;
18 }
19
20 // Do rest of validation
21 ...
22
23 // Retrieve session data
24 if( FAILED( RetrieveOrCreateSession( ) ) ) {
25 return HTTP_FAIL;
26 }
27
28 if( FAILED( UpdateHitCount( ) ) ) {
29 return HTTP_FAIL;
30 }
31
32 m_HttpResponse.SetContentType( "text/html" );
33 return HTTP_SUCCESS;
34}
The line in bold is the
magic call that gets us the ISessionStateService interface
pointer we need.
An Aside: The IServiceProvider Interface
The IServiceProvider interface is
actually a standard interface that was introduced back in the IE4
days. It hasn’t gotten a whole lot of attention, but implementing
it can give you a surprisingly powerful system. The definition is
actually quite simple:
1interface IServiceProvider : IUnknown {
2 HRESULT QueryService(
3 [in] REFGUID guidService,
4 [in] REFIID riid,
5 [out, iid_is(riid)] IUnknown ** ppvObject);
6};
The parameters of QueryService are
essentially identical to those of QueryInterface, and
QueryService acts a lot like QueryInterface: You
ask for a particular IID, and you get back an interface pointer.
There’s a major difference, though: QueryInterface is
required to return an interface pointer on the same object and obey
all the rules of COM identity. QueryService, on the other
hand, can (and usually does) return an interface pointer on a
different COM object.
This explains the guidService parameter
to the QueryService call: It’s specifying which particular
object we want to get the interface pointer to. This GUID doesn’t
need to be a CLSID, or an IID, or a CATID, or anything else. It’s
simply a predefined GUID that the developer chooses to represent
that particular service.
The IServiceProvider interface is how
ATL Server provides, well, services to the request handlers. When
you create your project via the ATL Server Project Wizard and you
choose session support, these lines get added to your ISAPI
extension class:
1// session state support
2typedef CSessionStateService<WorkerThreadClass,
3 CMemSessionServiceImpl> sessionSvcType;
4CComObjectGlobal<sessionSvcType> m_SessionStateSvc;
5
6public:
7
8BOOL GetExtensionVersion(HSE_VERSION_INFO* pVer) {
9 // ...
10 if (S_OK != m_SessionStateSvc.Initialize(&m_WorkerThread,
11 static_cast<IServiceProvider*>(this))) {
12 TerminateExtension(0);
13 return SetCriticalIsapiError(
14 IDS_ATLSRV_CRITICAL_SESSIONSTATEFAILED);
15 }
16 return TRUE;
17}
18
19BOOL TerminateExtension(DWORD dwFlags) {
20 m_SessionStateSvc.Shutdown();
21 BOOL bRet = baseISAPI::TerminateExtension(dwFlags);
22 return bRet;
23}
24
25HRESULT STDMETHODCALLTYPE QueryService(
26 REFGUID guidService, REFIID riid, void** ppvObject) {
27 if (InlineIsEqualGUID(guidService,
28 __uuidof(ISessionStateService)))
29 return m_SessionStateSvc.QueryInterface(riid, ppvObject);
30 return baseISAPI::QueryService(guidService, riid,
31 ppvObject);
32}
The
ISAPI extension creates a session-state service object as a
“global” object; you might remember CComObjectGlobal from
Chapter 4, “Objects in
ATL.” This object lives as long as the ISAPI extension object does
and basically ignores AddRef and Release counts.
The QueryService implementation checks to see if the
guidService parameter is equal to the
ISessionStateService method; if so, it simply calls
QueryInterface on the member session state service
object.
ATL Server uses this technique to provide several kinds of services to the request headers. If you have your own services that you want to provide across the application, this is a good way to do it.
Creating and Retrieving Sessions
So, we now have an ISessionService
pointer. The next step is to use that pointer to look up our
session, and to create one if it doesn’t exist.
The first question is, how do we know which session to grab? ATL Server has built-in support for the standard approach (a session cookie) and the flexibility to let you do your own session identification, if you need to.
Here’s how you retrieve a session using a session cookie:
1HRESULT ShowPostsHandler::RetrieveOrCreateSession( ) {
2 HRESULT hr;
3 CStringA sessionId;
4 m_HttpRequest.GetSessionCookie( ).GetValue( sessionId );
5 if( sessionId.GetLength( ) == 0 ) {
6 // No session yet, create one
7 const size_t nCharacters = 64;
8 CHAR szID[nCharacters + 1];
9 szID[0] = 0;
10 DWORD dwCharacters = nCharacters;
11 hr = m_spSessionStateSvc->CreateNewSession(szID,
12 &dwCharacters, &m_spSession) );
13 if( FAILED( hr ) ) return hr;
14
15 CSessionCookie theSessionCookie( szID );
16 m_HttpResponse.AppendCookie( &theSessionCookie );
17 }
18 else {
19 // Retrieve existing session
20 hr = m_spSessionStateSvc->GetSession(sessionId,
21 &m_spSession ) );
22 if( FAILED( hr ) ) return hr;
23 }
24 return S_OK;
25}
First, we grab the value of
the cookie. This gives us our session ID. If there isn’t a value,
we create the session via the
ISessionService::CreateNewSession method. This both
creates the session and returns the ID for the session created. We
then create a new session cookie and add it to the response. This
step is important, and you can easily forget it if you’re used to
other web frameworks that create sessions for you
automatically.
If there is a cookie value, we use the
ISessionService::GetSession method to get an
ISession interface pointer and connect back up to the
session.
Storing and Retrieving Session Data
When we have our ISession pointer, we
can store and retrieve values. ISession maps names (as
ANSI strings) to VARIANTS. Usage is pretty much what you’d
expect:
1HRESULT ShowPostsHandler::UpdateHitCount() {
2 CStringA sessionVarName = "mySessionVariable";
3 CComVariant hits;
4 if( FAILED(
5 m_spSession->GetVariable( sessionVarName, &hits ) ) ) {
6 // If no such session variable, GetVariable return E_FAIL.
7 // Gotta love nice specific HRESULTS
8 hits = CComVariant( 0, VT_I4 );
9 }
10 m_hits = ++hits.lVal;
11 return m_spSession->SetVariable( sessionVarName, hits ) );
12}
The ISession interface provides the
GetVariable and SetVariable methods to get and
save a single variable. There are also methods to enumerate the
session variables and control session timeouts.
Session State Implementations
One question about session management hasn’t been answered yet: Where is session data stored? The answer, as usual for ATL, depends on which template arguments you use.
Let’s look back at that type declaration in the ISAPI extension:
1typedef CSessionStateService<WorkerThreadClass,
2 CMemSessionServiceImpl> sessionSvcType;
The
CSessionStateService template takes two parameters: The
first is the worker thread class for the ISAPI extension. The
second is the class that implements the ISessionService
interface. In this case, we use CMemSessionServiceImpl,
which provides in-memory session storage. In-memory session-state
storage has the advantage of being very fast, but because it is
only in memory on the server, it doesn’t work in a server farm.
ATL Server provides the
CDBSessionServiceImpl as an alternative. This stores
session state in a database instead. The access to a session is
slower, but it can be shared across multiple machines in a farm.
Choose the appropriate service implementation based on your
requirements.
Data Caching
A smart caching strategy is often the difference between a site that comes up quickly and one that leave the users staring at the little spinning globe for the traditional 25 seconds before they go to anther site. ATL Server offers data-caching services to help you get below that magic time threshold.
Caching Raw Memory
The most basic caching service is the BLOB
cache. No, this isn’t a gelatinous alien that will try to digest
your hometown. This cache handles raw chunks of memory. Getting
hold of the cache is done just as when using the session
service – that is, you use the IServiceProvider
interface:
1HTTP_CODE ShowPostsHandler::ValidateAndExchange( ) {
2 ...
3 HRESULT hr = m_spServiceProvider->QueryService(
4 __uuidof(IMemoryCache), &m_spMemoryCache );
5 if( FAILED( hr ) ) return HTTP_FAIL;
6 ...
7}
When you have an IMemoryCache interface
pointer, you can stuff items into and pull them out of the cache.
The cache items are stored as name/value pairs, just like
session-state items. Instead of storing VARIANTs, however,
the BLOB cache stores void pointers.
Retrieving an item requires two steps. First, you must get a cache item handle:
1HRESULT ShowPostsHandler::GetWordOfDay(CStringA &result) {
2 HRESULT hr;
3 HCACHEITEM hItem;
4 hr = m_spMemoryCache->LookupEntry( "WordOfDay", &hItem );
5 if( SUCCEEDED( hr ) ) {
6 // Found it, pull out the entry
7 ...
8 }
9 else if( hr == E_FAIL ) {
10 // Not in cache
11 ...
12 }
13}
The LookupEntry method returns
S_OK if it found the item, and E_FAIL if it
didn’t. [7]
When we have the item handle, we can retrieve
the data from the cache. This is done via the GeTData
method, which returns the void* that was stored in the
cache, along with a DWORD giving you the length of the
item:
1HRESULT ShowPostsHandler::GetWordOfDay(CStringA &result) {
2 ...
3 // Found it, pull out the entry
4 void *pData;
5 DWORD dataLength;
6
7 hr = m_spMemoryCache->GetData( hItem, &pData, &dataLength );
8 if( SUCCEEDED( hr ) ) {
9 result = CStringA( static_cast< char * >( pData ),
10 dataLength );
11 }
12 m_spMemoryCache->ReleaseEntry( hItem );
13 ...
14}
The pointer that is returned from the
GeTData call actually points to the data that’s stored
inside the cache’s data structure; it’s not a copy. Because we
don’t want the cache to delete the item out from under us, we copy
it into our result variable.
The final call to ReleaseEntry is
essential for proper cache management. The BLOB cache actually does
reference counting on the items stored in the cache. Every time you
call LookupEntry, the refcount for the entry you found
gets incremented. ReleaseEntry decrements the refcount.
Entries with a refcount greater than zero are guaranteed to remain
in the cache. Because the whole point of using the cache is to
pitch infrequently used data, properly releasing entries when you
are finished with them is just as important as properly managing
COM reference counts. Unfortunately, there’s no
CCacheItemPtr smart pointer template to help. [8]
If you get that E_FAIL error code, you
typically want to load the cache with the necessary data for next
time. Doing so is fairly easy; you just call the Add
method:
1HRESULT ShowPostsHandler::GetWordOfDay(CStringA &result) {
2 ...
3
4 // Not in cache
5 char *wordOfTheDay = new char[ 6 ];
6 memcpy( wordOfTheDay, "apple", 6 );
7 FILETIME ft = { 0 };
8 hr = m_spMemoryCache->Add( "WordOfDay", wordOfTheDay,
9 6 * sizeof( char ), &ft, 0, 0, 0 );
10 ...
11}
This code allocates the memory for the item,
specifies an expiration time (via the FILETIME value,
where 0 means that it doesn’t expire), and places it into
the cache. The block of memory is now safely stored until the cache
gets flushed or scavenged; at that point, we have a memory
leak.
Why the memory leak? The cache is storing only
void pointers; it knows nothing about how the memory it
has been handed should be freed. It doesn’t run destructors,
either. To prevent memory leaks, there is a hook to provide a
deallocator, and it’s done on a per-entry basis. The last parameter
in the call to the Add method is an optional pointer to an
implementation of the IMemoryCacheClient interface, which
has a single method:
1interface IMemoryCacheClient : IUnknown {
2 HRESULT Free([ in ] const void *pvData);
3};
When an item is about to be removed from the
cache, if you provided an IMemoryCacheClient
implementation in the Add call, the cache calls the
Free method to clean up. In this example, you’d just need
to add a call to delete on the void pointer. Unfortunately, there’s no standard implementation
of this interface for use in the BLOB cache.
Caching Files
The BLOB cache is useful for storing small chunks of arbitrary data, but sometimes you need to store large chunks. The file-caching service lets you create temporary files on disk; when the cache item expires, it automatically deletes the disk file.
The file cache operates much like the BLOB
cache. You use IServiceProvider to get an
IFileCache interface pointer. The file cache uses handles,
just like the BLOB cache. The only major difference is that the
file cache stores filenames instead of chunks of memory.
Summary
ATL Server is a set of classes to build ISAPI applications in C++. A typical ATL Server project is made up of three major components. The first is an ISAPI extension DLL that implements the required ISAPI methods. In addition, the ISAPI extension provides a thread pool and request-dispatching service to keep the web server responsive.
The second component is the .srf or
stencil file. This is a file that contains replacements marked in
{{ }} pairs. The .srf file is processed by a
request-handler class, usually in a separate DLL. The third
component, the request handler, actually processes the HTTP request
and implements the replacements used in the .srf
files.
ATL Server also provides utility functions to make web development easier. Input validation is supported for numeric ranges and string length, and a regular expression engine is included for sophisticated string analysis. Caching services are also provided to help improve performance in heavily loaded systems.